ITコーディネータのシュウです。

上の写真は、昨年12月に仙台に行く機会があり、帰りが夜になったのですが、そのときに行われていた「2022SENDAI光のページェント」のイルミネーションの様子を撮ったものです。冬の仙台を明るくしたい」「杜の都を光の都へ」という想いで、1986年に始まったものらしいのですが、とても綺麗だということを聞いていたので、是非見てみたいと思い、車でその中を通って帰りました。定禅寺通の欅並木をメインステージとして、本当に大きな光のトンネルのようなイルミネーションで、とても感動しました。世界的に様々、暗いニュースが多い中で、ここを通る人たちの心に希望の明かりを灯そうという試みは、素晴らしいと感じました。
新しい1年が始まりましたが、2023年が、皆様にとって素晴らしい1年になりますようにと願いながら、今年もよろしくお願いいたします。
<本日の題材>
JSON出力(SQL Server)
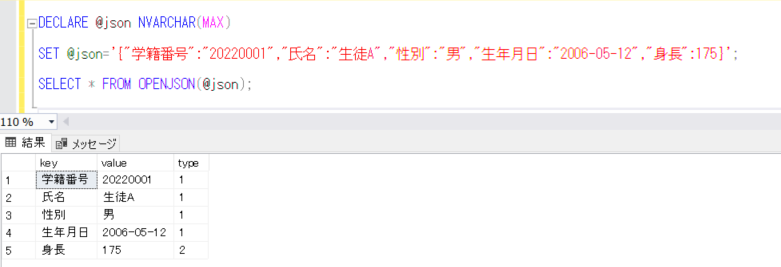
今回は、SQL ServerでJSONデータを利用できる件について、確認してみようと思います。
JSONは「JavaScript Object Notation」の略称で、開発当初はJavaScriptでの利用を前提に作られた、テキストをベースにした、軽量なデータ交換をおこなうためのフォーマットとして作られました。データの構造が単純なため、人間が見たときに一目でわかるようになっていますし、コンピュータから見た場合も、読み込んだり加工したりしやすい構造で、その使いやすさからCやJava、Pythonなど、多くのプログラミング言語で広く活用されています。例えば、JSON形式のデータは以下のようなものになります。
[
{ "Id": 1, "Name" : "山田", "Age" : 20 } ,
{ "Id": 2, "Name" : "高橋", "Age" : 22 } ,
{ "Id": 3, "Name" : "鈴木", "Age" : 19 }
]
CSVファイルよりは見た目がわかりやすく、XML形式よりは加工などがしやすいと言えます。
そのJSONフォーマットをSQLServerでも利用できるようにということで、SQL Server 2016からJSON対応機能が追加されています。その機能とは、「RDBMSの表形式のデータをJSONフォーマットに変換して出力できる」ことと、逆に「JSONフォーマットで入力したデータを、RDBMSの表形式に変換して格納できる」という機能になります。
例)
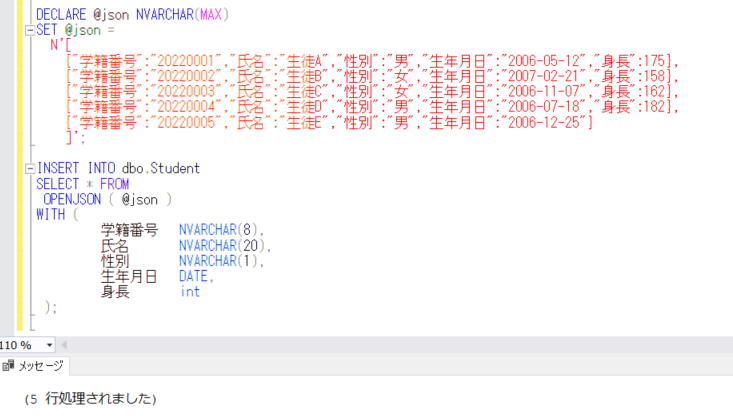
以前、ブログで扱ったことのある「Student」テーブルの定義を少し変更して、データを登録し、JSONフォーマットに変換して出力してみます。
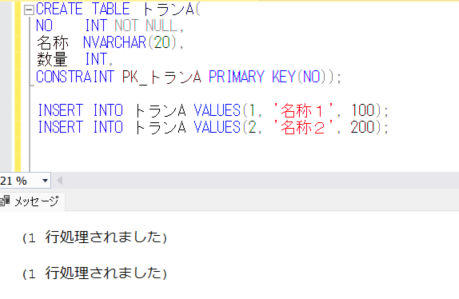
「Student」テーブルを下記のようなSQLで作成します。
CREATE TABLE dbo.Student(
学籍番号 NVARCHAR(8),
氏名 NVARCHAR(20),
性別 NVARCHAR(1),
生年月日 DATE,
身長 INT,
CONSTRAINT PK_Student PRIMARY KEY(学籍番号));
データを登録します。
INSERT INTO dbo.Student VALUES('20220001', '生徒A', '男', '2006-05-12', 175);
INSERT INTO dbo.Student VALUES('20220002', '生徒B', '女', '2007-02-21', 158);
INSERT INTO dbo.Student VALUES('20220003', '生徒C', '女', '2006-11-07', 162);
INSERT INTO dbo.Student VALUES('20220004', '生徒D', '男', '2006-07-18', 182);
INSERT INTO dbo.Student VALUES('20220005', '生徒E', '男', '2006-12-25', NULL);
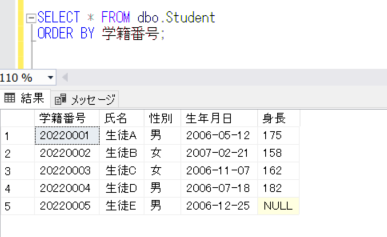
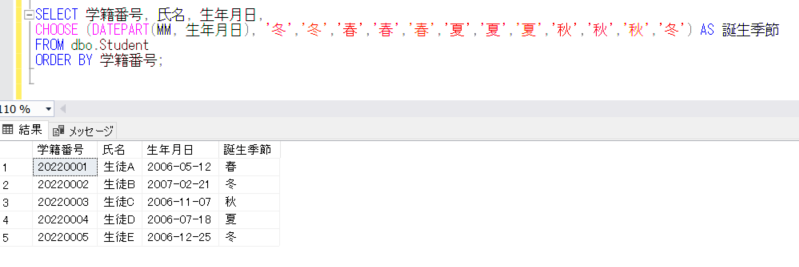
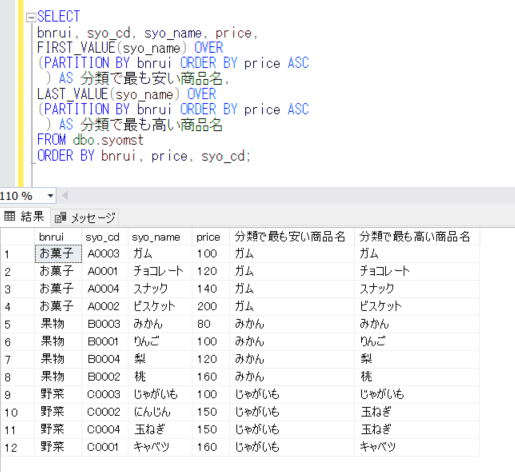
データを確認すると、
SELECT * FROM dbo.Student
ORDER BY 学籍番号;
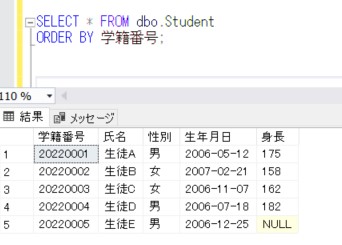
このSQLの最後に「FOR JSON AUTO」を追加します。
SELECT * FROM dbo.Student
ORDER BY 学籍番号 FOR JSON AUTO;
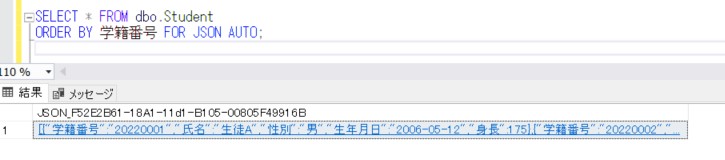
結果セットとして返ってくる列は1つのみで、列名は常に"JSON_F52E2B61-18A1-11d1-B105-00805F49916B"という値になり、指定はできません。そして、結果セットのデータがJSONフォーマットの値になっています。結果セットの値に改行を入れて整形すると以下のようになります。
[
{"学籍番号":"20220001","氏名":"生徒A","性別":"男","生年月日":"2006-05-12","身長":175},
{"学籍番号":"20220002","氏名":"生徒B","性別":"女","生年月日":"2007-02-21","身長":158},
{"学籍番号":"20220003","氏名":"生徒C","性別":"女","生年月日":"2006-11-07","身長":162},
{"学籍番号":"20220004","氏名":"生徒D","性別":"男","生年月日":"2006-07-18","身長":182},
{"学籍番号":"20220005","氏名":"生徒E","性別":"男","生年月日":"2006-12-25"}
]
出力されているJSONフォーマットを見ると、学籍番号、氏名、性別はNVARCHAR型なので、文字として、生年月日はDATE型なので、こちらもJSONフォーマットでは文字としてダブルクォーテーションで囲んで出力され、身長はINT型なので、数値として、ダブルクォーテーションで囲まれずに出力されているのがわかります。また、学籍番号:20220005のデータは、身長がNULLですが、NULLの場合JSONフォーマットでは、身長というキー名も出力されないというかたちになります。
この、データがNULLの場合はキー名も出力されないというのは、SQLのオプション指定で変更できます。INCLUDE_NULL_VALUES というオプションを最後に付けるかたちになります。
SELECT * FROM dbo.Student
ORDER BY 学籍番号 FOR JSON AUTO, INCLUDE_NULL_VALUES;

結果セットの値に改行を入れて整形すると以下のようになります。
[
{"学籍番号":"20220001","氏名":"生徒A","性別":"男","生年月日":"2006-05-12","身長":175},
{"学籍番号":"20220002","氏名":"生徒B","性別":"女","生年月日":"2007-02-21","身長":158},
{"学籍番号":"20220003","氏名":"生徒C","性別":"女","生年月日":"2006-11-07","身長":162},
{"学籍番号":"20220004","氏名":"生徒D","性別":"男","生年月日":"2006-07-18","身長":182},
{"学籍番号":"20220005","氏名":"生徒E","性別":"男","生年月日":"2006-12-25","身長":null}
]
学籍番号:20220005のデータに、「"身長":null」が出力されていることがわかります。
上記の FOR JSON句の「AUTO」オプションは、AUTOモードという意味で、自動的にJSON出力を書式設定してくれるものですが、「PATH」オプションを使用すると、下記のように「性別」項目以降を入れ子にするかたちのクエリを使用することで、入れ子になった出力をするようなことができます。
SELECT
学籍番号,
氏名,
性別 AS [情報.性別],
生年月日 AS [情報.生年月日],
身長 AS [情報.身長]
FROM dbo.Student
ORDER BY 学籍番号 FOR JSON PATH, INCLUDE_NULL_VALUES;
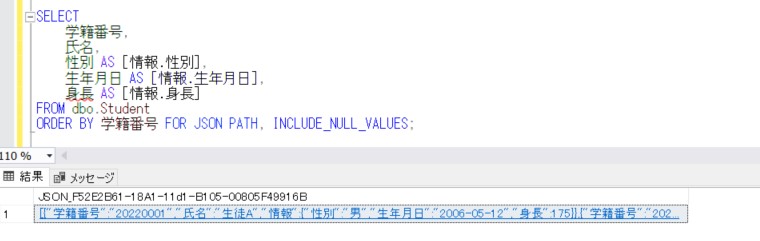
結果セットの値に改行を入れて整理すると、
[
{"学籍番号":"20220001","氏名":"生徒A","情報":{"性別":"男","生年月日":"2006-05-12","身長":175}},
{"学籍番号":"20220002","氏名":"生徒B","情報":{"性別":"女","生年月日":"2007-02-21","身長":158}},
{"学籍番号":"20220003","氏名":"生徒C","情報":{"性別":"女","生年月日":"2006-11-07","身長":162}},
{"学籍番号":"20220004","氏名":"生徒D","情報":{"性別":"男","生年月日":"2006-07-18","身長":182}},
{"学籍番号":"20220005","氏名":"生徒E","情報":{"性別":"男","生年月日":"2006-12-25","身長":null}}
]
「性別」「生年月日」「身長」が、「情報」という項目の入れ子として出力されているのが確認できました。
今日は以上まで
 にほんブログ村
にほんブログ村