ITコーディネータのシュウです。

2番目の娘が、土浦市の霞ケ浦総合公園で行われているイルミネーションを見てきたということで送ってきてくれた写真です。水郷桜イルミネーションと言うんですね。高さ25m・羽根直径20mのオランダ型風車のイルミネーションを中心に,市の花である『桜』や『土浦の花火』『霞ケ浦』『帆引き船』『ハス田』など土浦市の資源をモチーフにしたイルミネーションだそうです。私も行ってみたいですね。
さて、年末も間近に迫ってきました。ブログをアップしたいと思いつつも、日々の仕事に追われて、ヘトヘトです。そう言えば、先日まで日本でFIFAクラブワールドカップが行われ、開催国代表の鹿島アントラーズが、何と準優勝!それも、あのクリスティアーノ・ロナウド擁するレアル・マドリードを一時は逆転して追い込む場面もあり、最後は延長でのロナウドの2得点というさすがと思わせるゴールも見られた、とても面白い試合だったと思います。日本のJリーグのチームがあそこまでやるとはと、とても興奮しましたね。今後の日本のサッカー界にとても希望を持たせる活躍だったと思います。
話しは変わりますが、dbSheetClientのユーザー事例に、株式会社みうら様の事例が載りました。
Excelのインターフェースを活かした見積作成、及び納期・工程進捗管理システムを短期間で構築、内製化を実現し、ERPとの連携を効率化した事例ということで、お客様もとても喜ばれているようです。ご興味ある方は、是非こちらをご参照ください!
http://www.newcom07.jp/dbsheetclient/usrvoice/miura_system.html
なお、今回が今年最後のブログになりそうです。
1年間どうもありがとうございました。_m(. .)m_ 来年も、よろしくお願いいたします。
<本日の題材>
varchar(max)、nvarchar(max) (SQL Server)
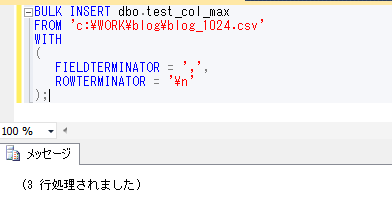
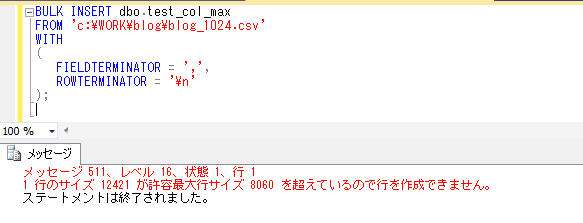
何回か前に、テーブルの項目数、レコード長の制限という内容で、SQL Serverの1レコードの制限が8060バイトという内容についてブログで取り上げましたが、SQL Server 2005から、大きな値のデータ型とよばれる、varchar(max)、nvarchar(max)型というものが機能として増えていますので、今回はこれを取り上げてみたいと思います。(他に、varbinary(max)型というバイナリデータを扱うものもあります)
システムの開発を行っていると、ときには、文字の桁数をどれくらいにしていいかを決めかねる場合があります。普通はそれほど多く入力しないけれども、ときにはいろいろな情報や説明を書きこむ必要があって、とても大きな桁数の入力をする可能性があるケース、そして、それも1レコード上に複数そのような項目が発生してしまう可能性があるケースなどもときに遭遇することもあります。その場合に、テーブルをうまく分割して対応するなどもありますが、いろいろと処理が複雑になってしまったりで悩んでしまうこともあると思います。
そんなときに、varchar(max)、nvarchar(max) を使うと、1項目の最大バイト数が varchar(max)では2^31-1、nvarchar(max)では文字数が最大2^30-1 というとてつもない大きさまで持つことができ、当然1レコードもその分は確保されるということになるため、テーブルの分割なども気にせずに対応することができることになります。
ちなみに、以前から text型、ntext型というサイズの大きなデータ型は用意されていましたが、whereの条件で = を使用することができないなどの制約がありました。将来のバージョンでは削除される予定ですので、これらを使うのではなく、varchar(max)、nvarchar(max)を使うように推奨されていますね。
今回は、それを試してみます。
例)
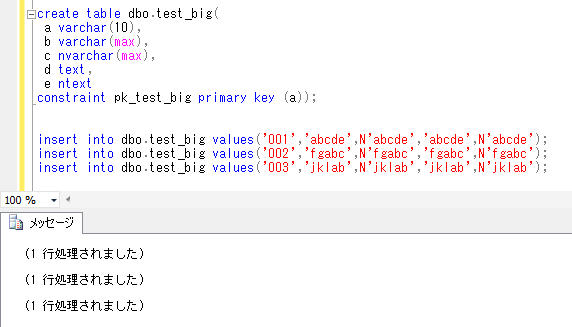
create table dbo.test_big(
a varchar(10),
b varchar(max),
c nvarchar(max),
d text,
e ntext
constraint pk_test_big primary key (a));
insert into dbo.test_big values('001','abcde',N'abcde','abcde',N'abcde');
insert into dbo.test_big values('002','fgabc',N'fgabc','fgabc',N'fgabc');
insert into dbo.test_big values('003','jklab',N'jklab','jklab',N'jklab');
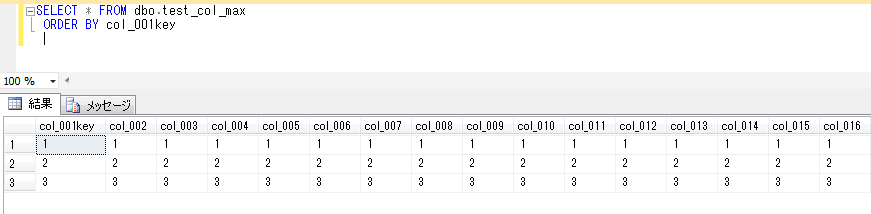
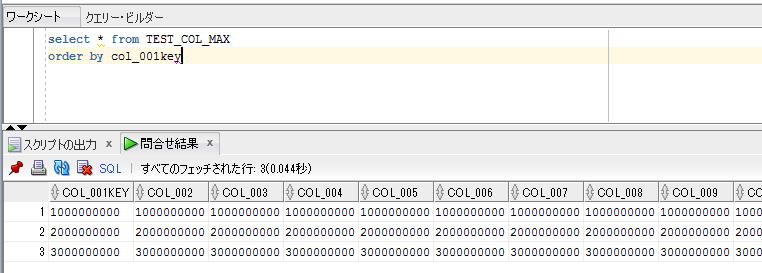
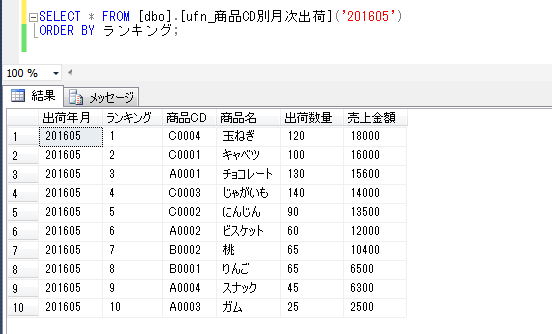
このときの、各項目のバイト数を確認してみると、
select
a, datalength(b) b_byte, datalength(c) c_byte, datalength(d) d_byte, datalength(e) e_byte
from dbo.test_big
order by a;
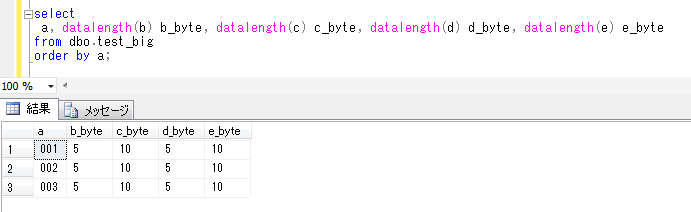
nvarchar(max)、ntext型は、5文字で10バイトを取っていて、varchar(max)、text型の2倍のサイズになっていることが確認できます。頭に n がつく nvarcharやncharなどは、unicode文字列をサポートするデータ型であり、2バイトを使用して1つの文字をエンコードする仕組みのため、文字数の2倍のバイト数が取られることになります。
それでは、varchar(max)、nvarchar(max)型は、whereの条件に「=」を使えますが、text型、ntext型では使用できないことを確認してみます。
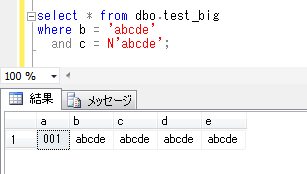
select * from dbo.test_big
where b = 'abcde'
and c = N'abcde';
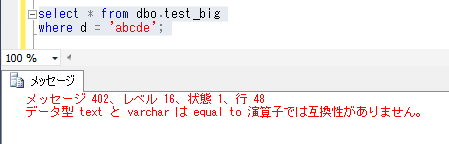
select * from dbo.test_big
where d = 'abcde';
select * from dbo.test_big
where e = N'abcde';
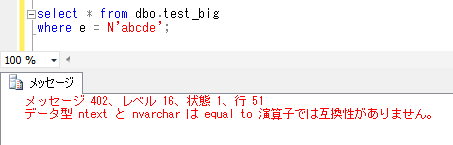
上記から、varchar(max)型、nvarchar(max)型は、通常の varchar, nvarchar 型と同様に、whereに「=」の条件を設定して使用できるけれども、text、ntext型では、whereに「=」演算子は使用できないことが確認できました。
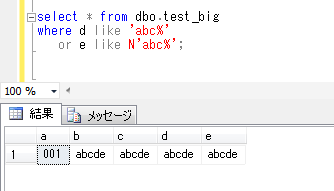
ちなみに、like 演算子は使用できます。
select * from dbo.test_big
where d like 'abc%'
or e like N'abc%';
次は、nvarchar(max)型を1つのテーブルに複数持ち、それぞれに8000文字(100文字ずつを改行して80行分)のデータを登録してみます。
create table dbo.test_big2(
a varchar(10),
b nvarchar(max),
c nvarchar(max),
d nvarchar(max),
e nvarchar(max),
constraint PK_test_big2 Primary key (a));
insert into dbo.test_big2(a,b,c,d,e) values(
'123',
N'12345678901234567890123456789012345678901234567890123456789012345678901234567890123456789012345678901234567890123456789012345678901234567890123456789012345678901234567890123456789012345678901234567890
……. (後ろは省略)
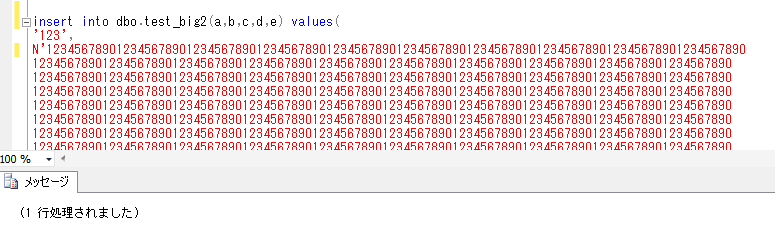
※画面は insert文の最初の部分のみ
すると、各項目のバイト数を抽出してみると、
select
a, datalength(b) b_byte, datalength(c) c_byte, datalength(d) d_byte, datalength(e) e_byte
from dbo.test_big2;
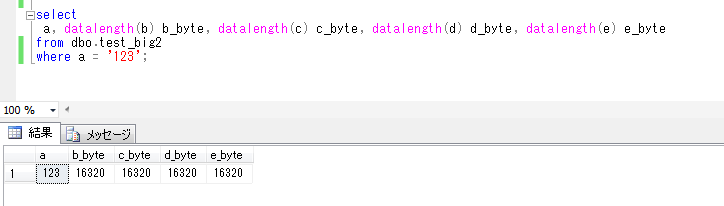
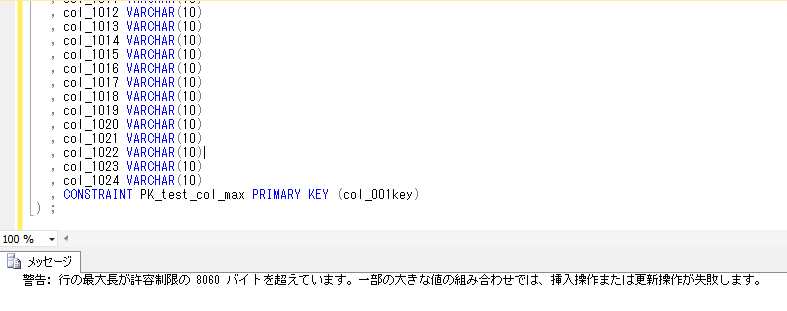
これは、8000文字分に加えて、改行コードはCHAR(13) - CR: キャリッジリターンと、CHAR(10) - LF: ラインフィードの組合せで合わせて2バイトになるので、8000+80*2=8160バイトのところ、nvarcharはvarcharの2倍のサイズを取るため、8160*2=16,320バイトとなっています。
上記から、1レコードの合計のレコード長も、65,283バイトとなり、以前紹介した8,060バイトの壁も問題なく超えて、長いサイズのレコードが登録できることが確認できました。
今日は以上まで
にほんブログ村