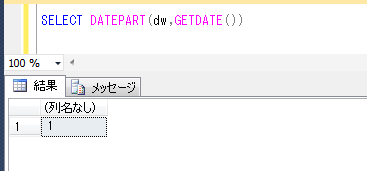
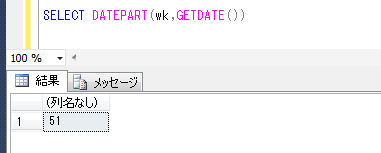
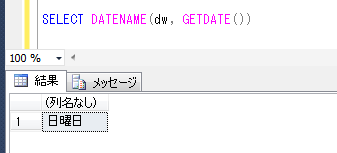
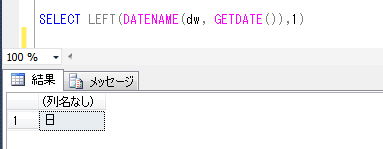
ITコーディネータのシュウです。

4月に入り、学校や多くの職場で年度が新しくなって、心機一転出発された方も多いと思います。
我が家の長女も、専門学校を卒業して、新しく社会人として出発しました。また、娘の一人は高校受験を何とかクリアして、高校生として出発しました。
自分のその当時のことを思い出しながら、子供たちもひとりひとり、人生の様々な試練や関門にぶつかりながら、少しずつ成長していく姿を見ると、感慨深いものがあります。
<本日の題材>
UTL_FILEパッケージ
前回、前々回と、ORACLEのパッケージについて取り上げました。今回もその続きで、ORACLE側で用意されているユーティリティ・パッケージの一つである、UTL_FILEパッケージについて見てみたいと思います。
UTL_FILEパッケージを使うことで、PL/SQLでOSのテキストファイルの読み書きができます。
そのためには、あらかじめアクセス可能なディレクトリを設定しておかなければなりません。この、ディレクトリ・オブジェクトの作成は、管理ユーザで行い、その後、そのディレクトリの読み書きを行う権限を、実行するユーザに与える必要があります。
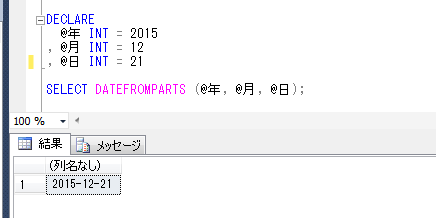
構文:
CREATE [OR REPLACE] DIRECTORY <ディレクトリ名>
AS ‘<ディレクトリ・パス>’
例) SYSDBA権限でログインし、ディレクトリを作成します。
CREATE OR REPLACE DIRECTORY temp_dir
AS 'C:\temp';
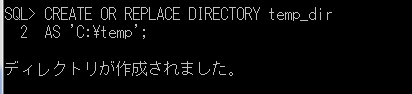
※このディレクトリは、サーバ上のディレクトリになります。
UTL_FILEパッケージを使ってファイルを読み書きするユーザ「BLOG」にディレクトリに対する読込権限と書き込み権限を付与します。
GRANT READ, WRITE ON DIRECTORY temp_dir TO blog;
![]()
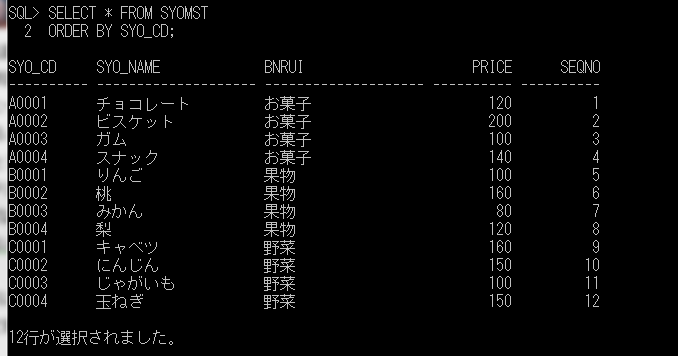
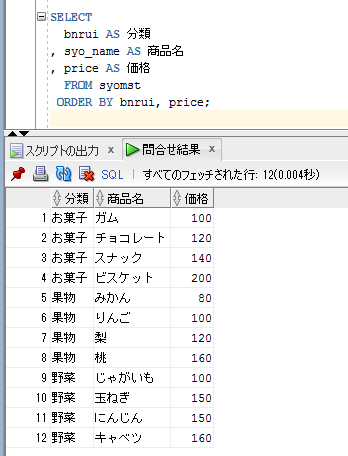
準備はできましたので、「商品マスタ(syomst)」のデータを、C:\temp ディレクトリ上に、「syomst.txt」という名前のテキストファイルに出力して保存するというプロシージャを、UTL_FILEパッケージを使って作成してみます。
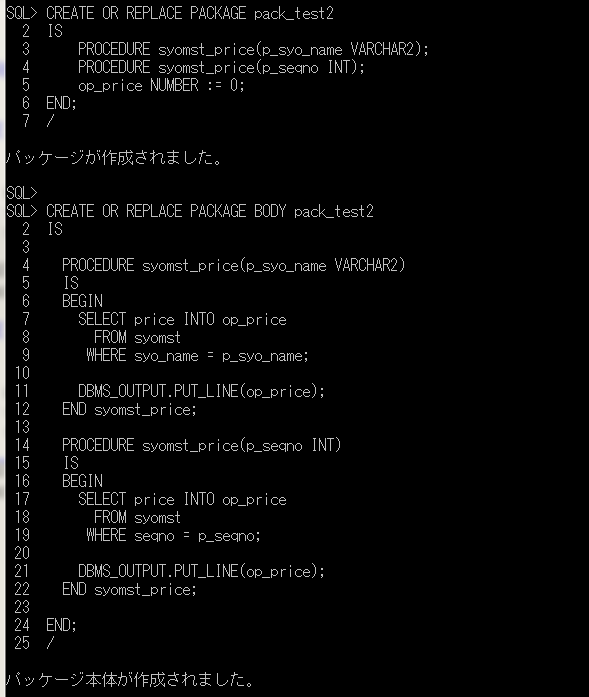
CREATE OR REPLACE PROCEDURE file_output_syomst
IS
CURSOR cur_syomst IS
SELECT
syo_cd||','||syo_name||','||bnrui||','||price||','||seqno AS syomst_data
FROM syomst
ORDER BY syo_cd;
--ファイル・ハンドルを受け取る変数の定義(1)
write_file UTL_FILE.FILE_TYPE;
BEGIN
--ファイルのオープン(2) (パラメータとして、ディレクトリ、ファイル名、オープンモード)
write_file := UTL_FILE.FOPEN('TEMP_DIR', 'syomst.txt', 'a');
--カーソルのループ
FOR syomst_rec IN cur_syomst LOOP
--データを1行ずつファイルに書き込む(3)
UTL_FILE.PUT_LINE(write_file, syomst_rec.syomst_data);
END LOOP;
--ファイルのクローズ(4)
UTL_FILE.FCLOSE(write_file);
EXCEPTION
WHEN OTHERS THEN
DBMS_OUTPUT.PUT_LINE('SQLCODE');
DBMS_OUTPUT.PUT_LINE('SQLERRM');
UTL_FILE.FCLOSE(write_file);
END;
/
使い方としては、まず、ファイル操作を行うためにはファイルごとにファイル・ハンドルというものが必要であり、それを格納する変数の定義を、UTL_FILEパッケージのFILE_TYPE型で定義します(1)。
その次に、FOPENファンクションを使用してファイルをオープンします。このFOPENファンクションは、戻り値としてファイルハンドルを戻します。構文は以下です。
UTL_FILE.FOPEN (
location IN VARCHAR2
,filename IN VARCHAR2
,open_mode IN VARCHAR2
[,max_linesize IN BINARY_INTEGER]
)
RETURN file_type;
各パラメータについて説明します。
・location:
ファイルのディレクトリ位置。この文字列はディレクトリのオブジェクト名で、大/小文字が区別される。デフォルトは大文字。ユーザーがFOPENを実行するには、このディレクトリに対する読取り権限が付与されている必要がある。
・filename: 拡張子(ファイル・タイプ)も含めたファイル名。
・open_mode: ファイルのオープン方法を指定
r -- テキストの読込み
w -- テキストの書込み
a -- テキストの追加
rb -- バイトの読込み
wb -- バイトの書込み
ab -- バイトの追加
・max_linesize:
改行文字を含むこのファイルの1行当たりの最大文字数(最小値は1、最大値は32767)。デフォルトは1024文字。
ファイルをオープンしたら、PUT_LINEプロシージャで1行のデータを書き込みます(3)。
※ファイルへの書き込みには、いくつかのプロシージャがあります。
UTL_FILE.PUT_LINE(ファイルハンドル, 文字列)
--ファイルにデータを書き込み、最後に改行コードも書き込む。
UTL_FILE.PUT(ファイルハンドル, 文字列)
--改行コードを付けずに、ファイルにデータを書き込む。
UTL_FILE.NEW_LINE(ファイルハンドル, 行数)
--改行コードのみをファイルに書き込む。
書込みが終了したら、FCLOSEプロシージャでOSファイルをクローズします(4)。
それでは、このプロシージャを実行してみます。
EXECUTE file_output_syomst
![]()
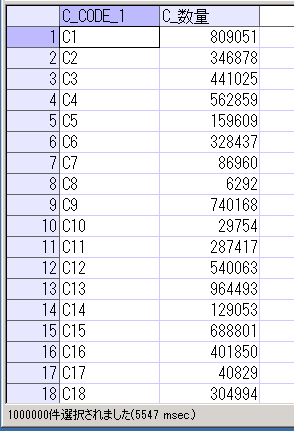
実行後、サーバの c:\temp ディレクトリに作成されたファイル「'syomst.txt」の中身を確認してみます。
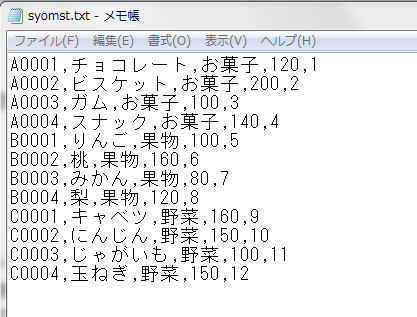
商品マスタのデータが、テキストファイルに出力されていることが確認できました。
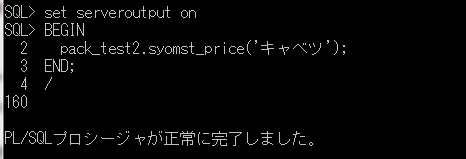
次に、先ほど作成したテキストファイル「syomst.txt」を読込んで、画面に出力するプロシージャを作成します。
CREATE OR REPLACE PROCEDURE file_read_txt
IS
--ファイル・ハンドルを受け取る変数の定義(1)
read_file UTL_FILE.FILE_TYPE;
V_DATA VARCHAR2(32767);
BEGIN
--ファイルのオープン(2)
read_file := UTL_FILE.FOPEN('TEMP_DIR', 'syomst.txt', 'r', 32767);
--ループ
LOOP
--ファイルハンドルから1行ずつデータを読込む(3)
UTL_FILE.GET_LINE(read_file, V_DATA, 32767);
--画面に表示する
DBMS_OUTPUT.PUT_LINE(V_DATA);
END LOOP;
EXCEPTION
WHEN NO_DATA_FOUND THEN
--読込む行がなくなると、ファイルをクローズする(4)
UTL_FILE.FCLOSE(read_file);
END;
/
ここでも、まずファイル・ハンドルを受け取る変数の定義を行い(1)、その後、FOPENファンクションで読込モードでテキストファイルをオープンします(2)。その後、GET_LINEプロシージャで1行ずつデータを読込み(3)、DBMS_OUTPUT.PUT_LINEで画面に出力します。
※GET_LINEで読込むファイルは、読込モード(r)でオープンしておく必要があります。違うモードの場合には、実行時INVALID_OPERATION例外が発生します。
読込む行がなくなると「NO_DATA_FOUND例外」が発生するので、FCLOSEプロシージャでファイルをクローズします(4)。
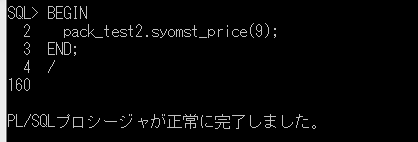
これを実行してみます。
SET SERVEROUTPUT ON
EXECUTE file_read_txt
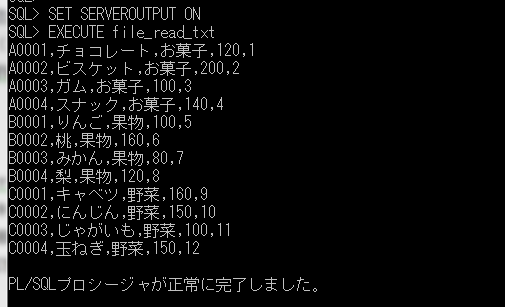
テキストファイル「syomst.txt」の内容を読込んで画面に表示することができました。
今日は以上まで
にほんブログ村