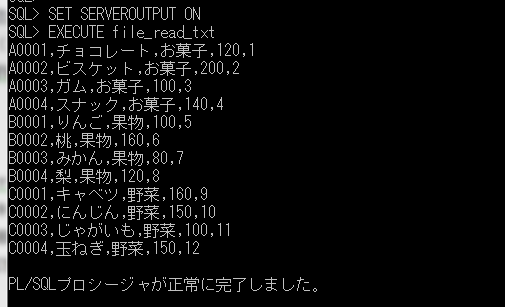
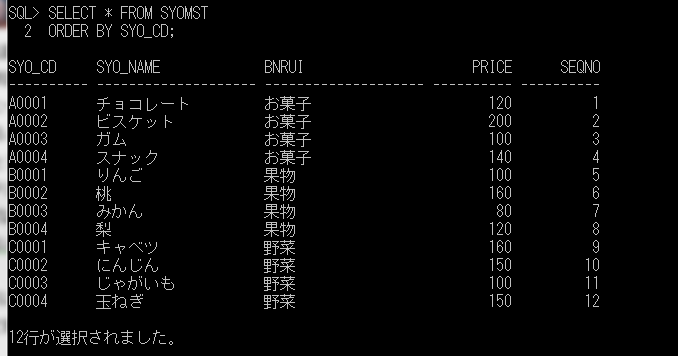
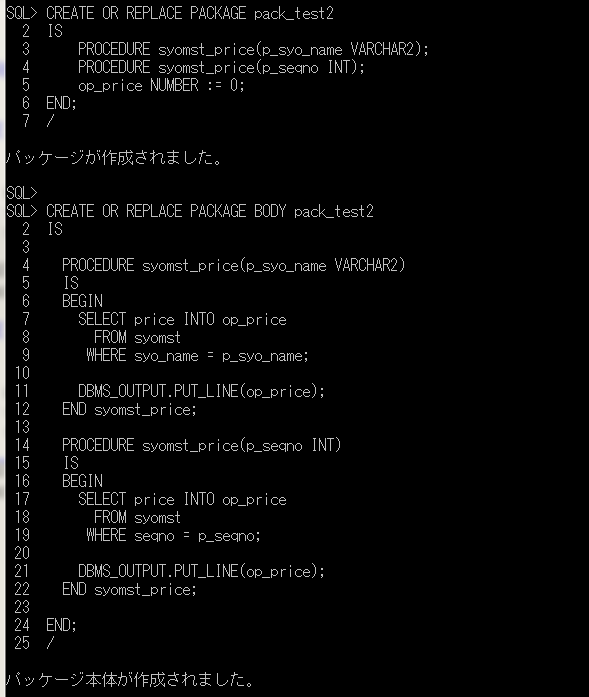
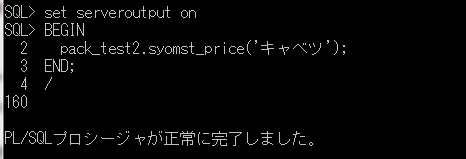
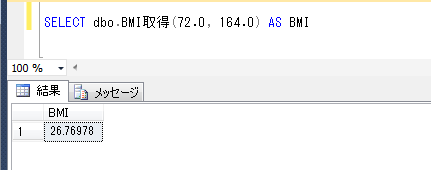
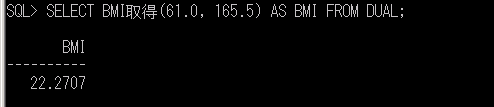
ITコーディネータのシュウです。

この写真は、住んでいるところの近くにある、関東最古の大社の一つと言われている「鷲宮神社」の鳥居が再建されている様子です。以前、ブログで人気まんが作品『らき☆すた』の舞台となった神社ということで取り上げ、この神社の鳥居の写真を載せたことがありましたが、2018年8月11日に、それまで建っていた鳥居が老朽化のために倒壊してしまいました。倒壊した鳥居は、100年以上前に建てられた木製のものでしたが、老朽化で、根本のほうがボロボロだったようです。それ以降、解体されて何もない状態でしたが、今回鳥居が再建されることになり、12月3日の祭典終了後から、通れるようになるということです。鳥居がなくて寂しい思いがしていましたが、立派な鳥居が再建されて、とても嬉しい気がします。
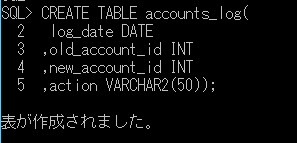
<本日の題材>
ネイティブコンパイルストアド プロシージャ(SQL Server)
前回のブログで、In-Memory OLTP 機能のメモリ最適化テーブル変数というものを取り上げましたが、今回はそれに関連する内容として、ネイティブコンパイルストアドプロシージャについて、試してみたいと思います。これは、メモリ最適化テーブルでの利用を想定したストアドプロシージャーです。
通常のSQL文によるクエリは、実行時にコンパイルしマシン語に変換したのちに実行されますが、ネイティブコンパイルストアドプロシージャーでは、マシン語に変換した状態のストアドプロシージャーをメモリに読み込ませておくため、従来のクエリよりも素早く実行できるのが特徴です。
ネイティブコンパイルとは、プログラミングの構造をネイティブコードに変換する処理であり、追加のコンパイルまたは解釈を必要としないプロセッサ命令で構成されると説明されています。
https://docs.microsoft.com/ja-jp/sql/relational-databases/in-memory-oltp/native-compilation-of-tables-and-stored-procedures?view=sql-server-ver15
例)
今回は、前回のメモリ最適化テーブル変数を使った処理とほぼ同様の内容を、ネイティブコンパイルストアドプロシージャで実行するようにしてみたいと思います。
ネイティブコンパイルストアドプロシージャの基本的な構文は以下となります。
CREATE PROCEDURE ストアドプロシージャ名
パラメーター定義
WITH
NATIVE_COMPILATION,
SCHEMABINDING
AS
BEGIN ATOMIC
WITH (
TRANSACTION ISOLATION LEVEL = SNAPSHOT,
LANGUAGE = N'japanese')
-- 実行したいステートメント
END
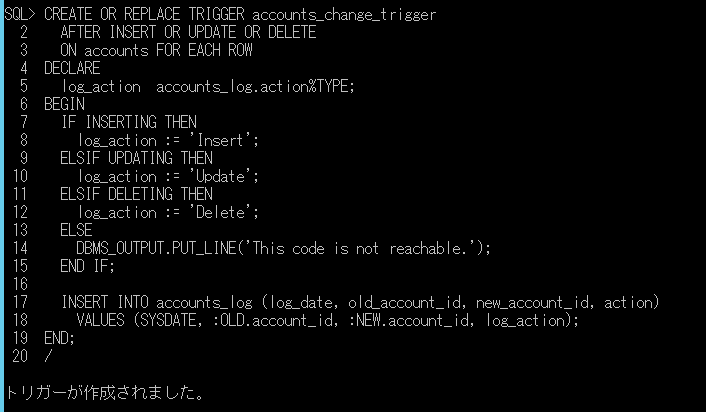
ネイティブコンパイルストアドプロシージャを作成するには、CREATE PROCEDURE 文で「WITH NATIVE_COMPILATION」、「SCHEMABINDING」を指定する必要があります。「BEGIN ATOMIC」と「END」で行いたい処理を囲むかたちになり、「TRANSACTION ISOLATION LEVEL」でトランザクションの分離レベルを指定します。LANGUAGE は、日付フォーマットやシステムメッセージをどの言語にするかを指定するもので、「japanese」とすることで、日本語の日付フォーマット、およびメッセージを表示できるようになります。
それでは、前回のブログの内容に合わせたネイティブコンパイルストアドプロシージャを作成します。まず最初に、今回は、変数ではなく、メモリ最適化テーブルを作成します。
CREATE TABLE dbo.mem_test_tab(
id numeric(8)
,名前 nvarchar(20)
,区分 nvarchar(2)
,ポイント int
,CONSTRAINT PK_mem_test_tab PRIMARY KEY
NONCLUSTERED HASH (id) WITH ( BUCKET_COUNT = 500000 )
) WITH ( MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA)
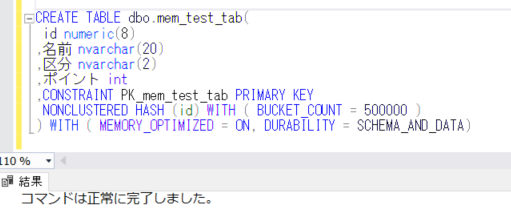
ここで、プライマリーキーのところでハッシュインデックスを設定し、さらに、WITHの後に「MEMOERY_OPTIMIZES=ON」と、「DURABILITY」を設定します。「DURABILITY」には、「SCHEMA_AND_DATA」と「SCHEMA_ONLY」が指定できます。SCHEMA_AND_DATA は、テーブルに持続性があり、変更がディスクに保存され、再起動またはフェールオーバー後も存続することを示しますが、SCHEMA_ONLY は、テーブルに持続性がないことを示します。
前回は、変数でしたので、一連の処理の中でデータを変数にセットしましたが、今回は、先ほど作成したメモリ最適化テーブルに、最初に50万件のデータを登録しておきます。
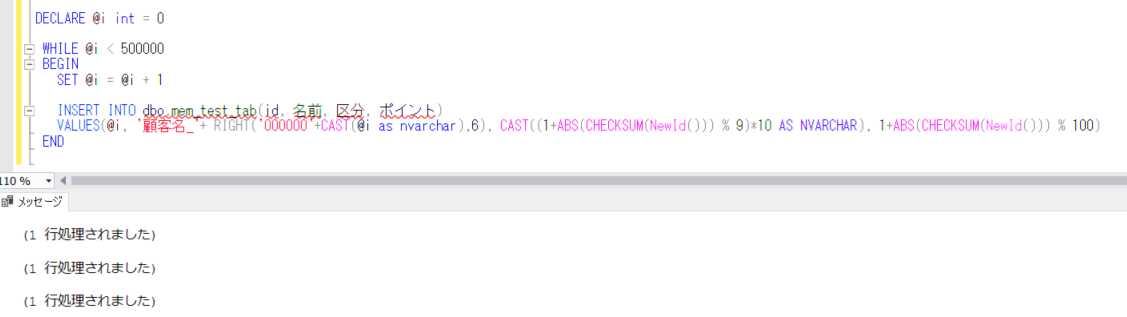
DECLARE @i int = 0
WHILE @i < 500000
BEGIN
SET @i = @i + 1
INSERT INTO dbo.mem_test_tab(id, 名前, 区分, ポイント)
VALUES(@i, '顧客名_'+ RIGHT('000000'+CAST(@i as nvarchar),6), CAST((1+ABS(CHECKSUM(NewId())) % 9)*10 AS NVARCHAR), ABS(CHECKSUM(NewId())) % 100)
END
データを確認してみます。
SELECT * FROM dbo.mem_test_tab
ORDER BY id;
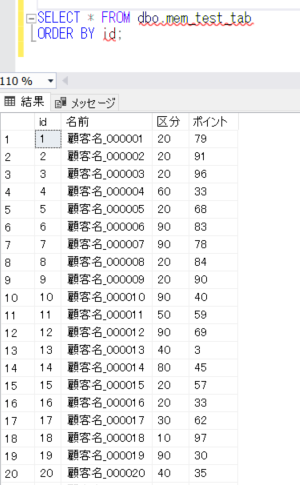
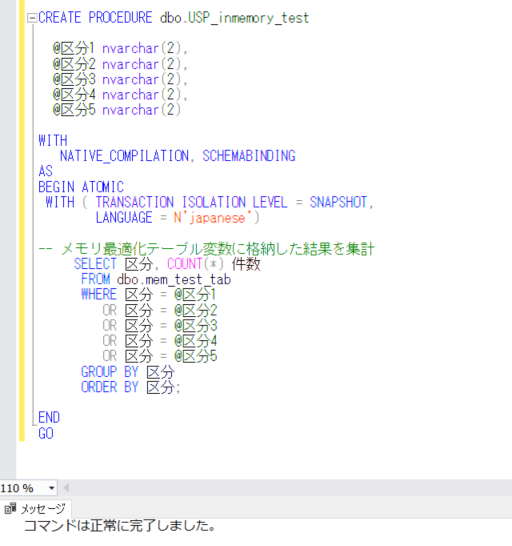
それでは、ネイティブコンパイルストアドプロシージャを作成します。
CREATE PROCEDURE dbo.USP_inmemory_test
@区分1 nvarchar(2),
@区分2 nvarchar(2),
@区分3 nvarchar(2),
@区分4 nvarchar(2),
@区分5 nvarchar(2)
WITH
NATIVE_COMPILATION, SCHEMABINDING
AS
BEGIN ATOMIC
WITH ( TRANSACTION ISOLATION LEVEL = SNAPSHOT,
LANGUAGE = N'japanese')
-- メモリ最適化テーブル変数に格納した結果を集計
SELECT 区分, COUNT(*) 件数
FROM dbo.mem_test_tab
WHERE 区分 = @区分1
OR 区分 = @区分2
OR 区分 = @区分3
OR 区分 = @区分4
OR 区分 = @区分5
GROUP BY 区分
ORDER BY 区分;
END
GO
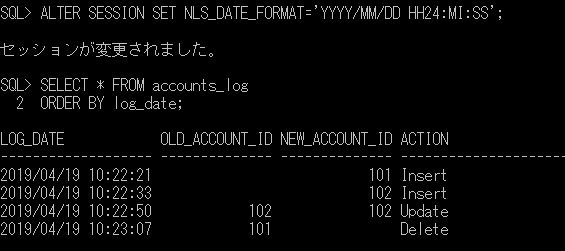
ネイティブコンパイルストアドプロシージャを実行します。
DECLARE @区分1 nvarchar(2) = '20',
@区分2 nvarchar(2) = '40',
@区分3 nvarchar(2) = '50',
@区分4 nvarchar(2) = '70',
@区分5 nvarchar(2) = '90';
EXEC dbo.USP_inmemory_test @区分1, @区分2, @区分3, @区分4, @区分5
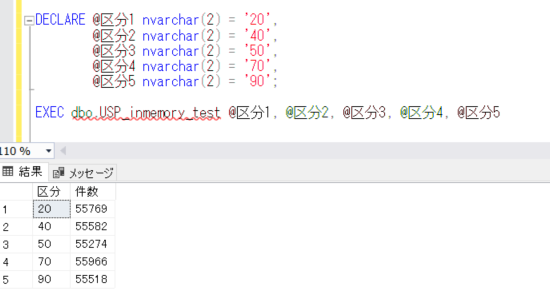
こちらも、ほとんど時間はかからずに結果が表示されました。
今回は、ネイティブコンパイルストアドプロシージャを作成して、動作することを確認しました。
今日は以上まで
にほんブログ村