ITコーディネータのシュウです。

筑波山に行ったときに、頂上付近で撮った写真です。私ははじめてだったのですが、何度も行ったことのある知人数人と一緒に、子供たちを連れて行ってきました。
筑波山は関東地方に人が住むようになったころから、信仰の対象として仰がれてきたということで、男体山(標高871m)と女体山(標高877m)という2つの山をいざなぎ、いざなみの神として仰いできたということです。山の中腹に筑波山神社の拝殿があり、頂上付近にも写真のような本殿があります。
頂上からはまわりが一望できて、晴れていれば素晴らしい景色になります。ロープウェイもありましたが、頑張って子供たちと登りました。ただし、結構急な坂もあり、久しぶりの運動で、登るのが大変でした。あらためて年を感じさせられました。
<本日の題材>
UNION、UNION ALL演算子
前回、前々回と集合演算の差、積を行う演算子について見ました。順番が逆になってしまった気がしますが、今日は複数の検索結果を統合する和集合を求める演算子について見てみます。
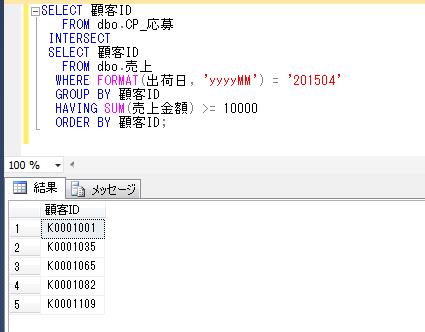
複数のSELECT文での問い合わせの結果に対して、和集合を抽出する演算子として、UNION、UNION ALLがあります。この演算子は、Oracle、SQL Serverともに使用できます。
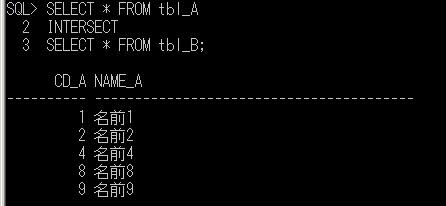
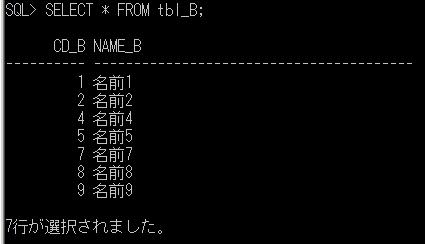
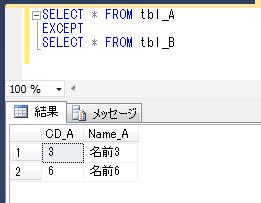
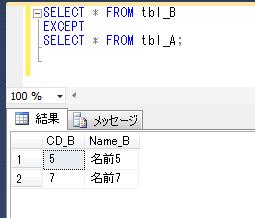
前回の抽出で使用したtbl_A、tbl_Bを利用して、少なくともどちらかのテーブルに存在するレコードを抽出してみます。このとき、重複するレコードは1行にまとめて表示します。
(SQL Serverで確認)
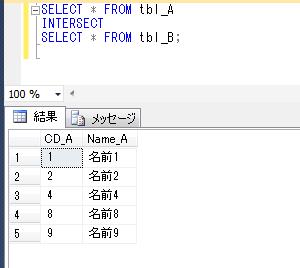
SELECT * FROM tbl_A
UNION
SELECT * FROM tbl_B;
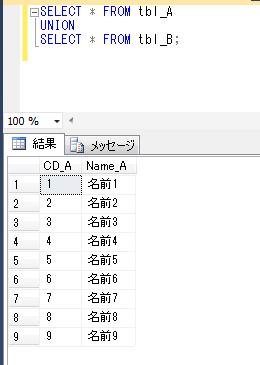
前々回、tbl_A、tbl_B のデータを確認していますが、たしかに、tbl_A、tbl_B のどちらかに存在するレコードが全て抽出されました。
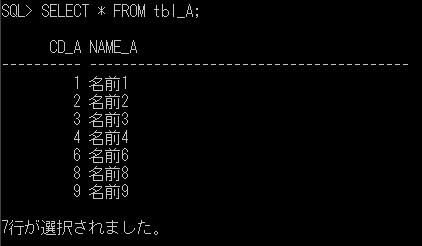
ここで、重複する行を1つにまとめずに、そのまま抽出する場合には、「UNION ALL」句を使用します。上記の例を、UNION ALLを使用して実行すると、
SELECT * FROM tbl_A
UNION ALL
SELECT * FROM tbl_B;
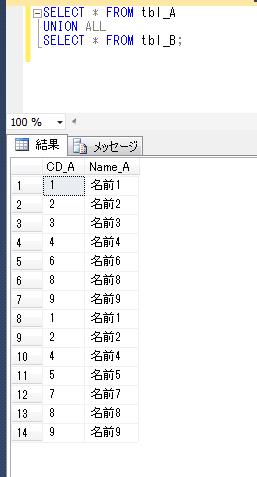
tbl_A、tbl_B のデータが重複データをまとめずに全て抽出されているのが確認できます。
※4パフォーマンスの観点から言うと、重複データを1行にまとめる処理(DISTINCT、UNION、INTERSECT、MINUSなど)は暗黙的にソート処理を行うため、その分処理が重くなり、レスポンスとしては遅くなる傾向があります。重複するデータがないということがあらかじめ分かっている場合には、和集合の場合はUNIONではなくUNION ALLを使用するようにしたほうがよいと言えます。
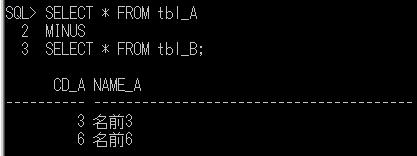
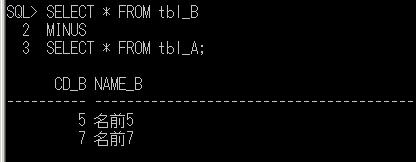
前々回で、同じ構造の2つのテーブルA、Bがあったとして、その2つのテーブルが完全に一致しているかどうかを確認するために、MINUS演算子を使用する例を上げましたが、一致するかどうかだけを確認したいならば、UNIONを使って確認するという方法もあります。
A, Bどちらも同じ行数のレコードが存在しているという状況がわかっていれば、下記のSQLを実行します。
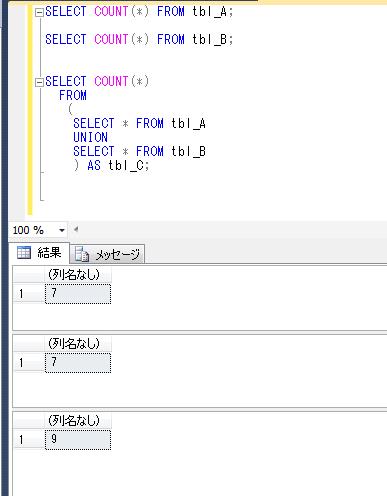
SELECT COUNT(*)
FROM
(
SELECT * FROM tbl_A
UNION
SELECT * FROM tbl_B
) AS tbl_C;
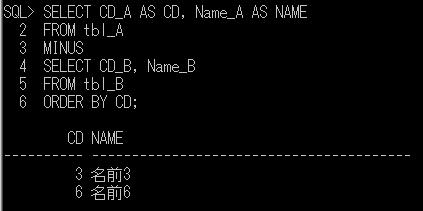
この結果が、A, B のテーブルのレコード数と一致していれば、A、Bは一致しているということができることになります。
ちなみに、上のサンプルデータで試した場合、以下のようになり、tbl_A、tbl_Bは一致していないことがわかります。
※Oracleでも同様の処理が可能です。
今日は以上まで
にほんブログ村