ITコーディネータのシュウです。

先月、会社の同僚と海釣りに行ってきました。
横浜の金沢八景の近くの海で、釣り船を予約して楽しんできました。その日はとてもよい天気で、アジ、サバ、イシモチなどが結構たくさん釣れましたね。私は最初なかなか釣れなくて、悪戦苦闘していたのですが、隣にいた釣り好きの先輩においては、竿を投げればすぐに引きが来る感じで、本当にびっくりです。同じようにやっているつもりなのに、どこかが違うんですね。やはり釣りは奥が深い!それでも、後半は多少釣れたこともあり、楽しむことができました。
上の写真は、船から八景島シーパラダイスのジェットコースターを撮ったものです。
釣れた魚は、その日のうちにさばいて刺身にして食べました。アジがぷりぷりしてとっても美味しかった。魚好きの妻も、美味しいと喜んでくれたので、よかった。\(^▽^)/
さて、今年も残りわずかとなりました。風邪など引かないで、よい年を迎えられますことをお祈りいたします。来年も、よろしくお願いいたします。
<本日の題材>
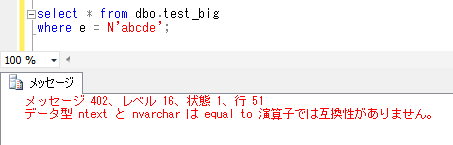
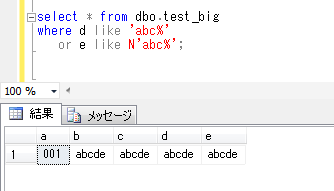
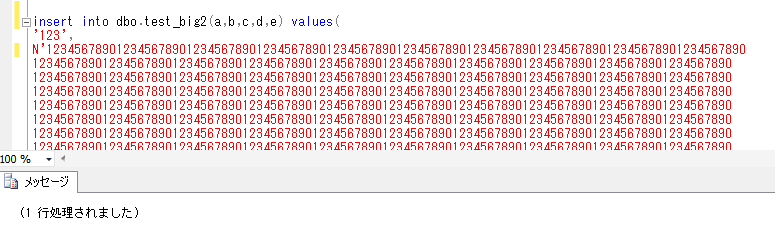
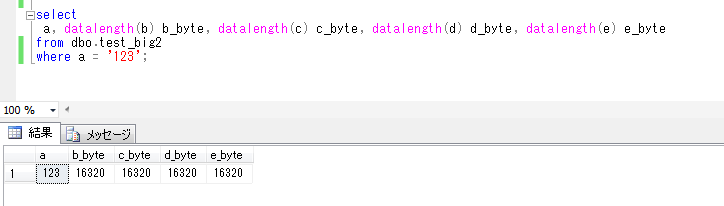
計算列(SQL Server)
SQL Serverで、計算列というものがあるということなので、試してみたいと思います。
例)
以前、身長と体重からBMI(肥満指数)をストアド・ファンクションを使って求めたことがありましたが、今回は計算列でこれを行ってみたいと思います。
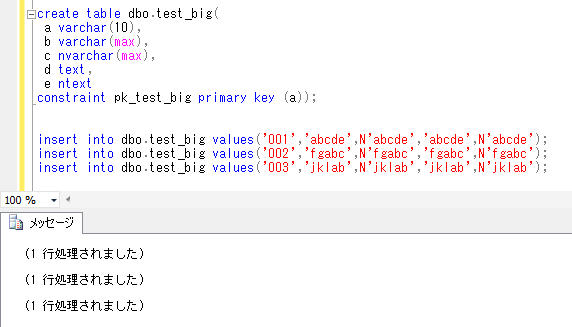
CREATE TABLE dbo.syain_health(
id INT
,height DECIMAL(5,1)
,weight DECIMAL(5,1)
,bmi AS (
weight /(height/100 * height/100))
,CONSTRAINT PK_syain_health PRIMARY KEY (id));
テーブル作成後に、テーブルの定義を、SQL Server Management Studio で確認すると、
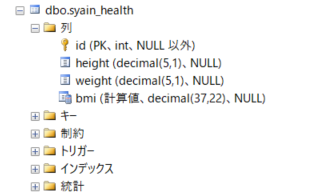
最後の「bmi」項目が計算列になります。
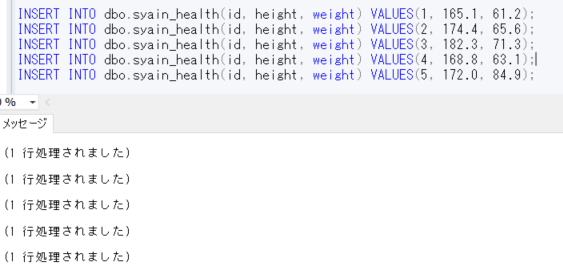
それでは、データを登録してみます。このとき、計算列にはInsertしません。
INSERT INTO dbo.syain_health(id, height, weight) VALUES(1, 165.1, 61.2);
INSERT INTO dbo.syain_health(id, height, weight) VALUES(2, 174.4, 65.6);
INSERT INTO dbo.syain_health(id, height, weight) VALUES(3, 182.3, 71.3);
INSERT INTO dbo.syain_health(id, height, weight) VALUES(4, 168.8, 63.1);
INSERT INTO dbo.syain_health(id, height, weight) VALUES(5, 172.0, 84.9);
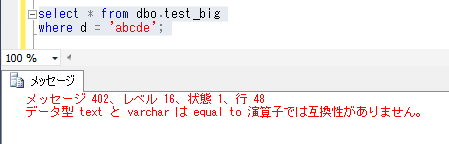
計算列にデータを登録しようとすると、下記のようにエラーが出ます。
INSERT INTO dbo.syain_health(id, height, weight, bmi) VALUES(6, 176.0, 73.5, 25.3);

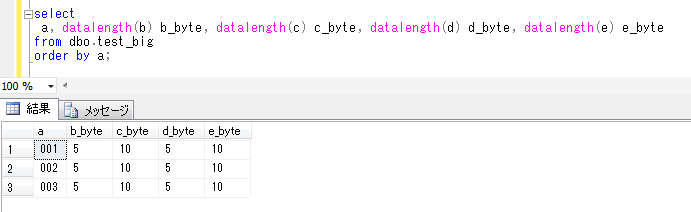
それでは、データをSELECTしてみます。
SELECT * FROM dbo.syain_health
ORDER BY id;
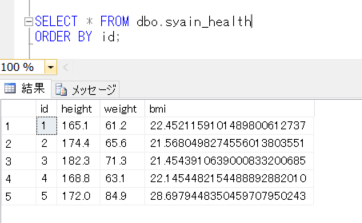
計算列で指定した「bmi」列は、自動的に計算されて抽出されていることが確認できます。
また、計算列にはインデックスを作成することもできます。
データを100万件ほど作成して、インデックスの有無によるレスポンスを比較してみます。
身長は、140センチ以上200センチ以内、体重は40キロ以上100キロ以内でランダムに作成してみます。このとき、RAND関数を利用してみます。RAND関数は、0~1までの範囲の乱数をfloat型で取得するものです。
DECLARE
@v_count INT = 5; -- id は既に1~5は作成済なので初期値を5
WHILE @v_count < 1000000
BEGIN
SET @v_count = @v_count + 1;
INSERT INTO dbo.syain_health(id, height, weight)VALUES
(@v_count, ROUND(140+RAND() * 600/10,1), ROUND(40+RAND() * 600/10,1));
END;
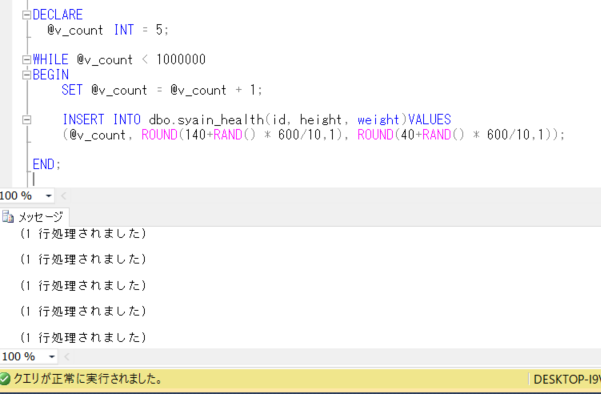
再度データを確認してみます。
SELECT * FROM dbo.syain_health
ORDER BY id;
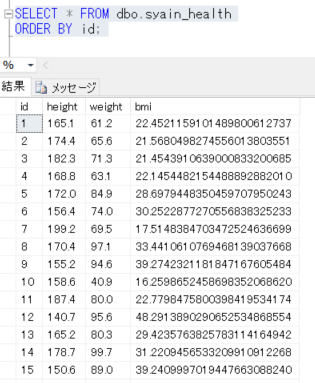
件数を確認すると、
SELECT COUNT(*) FROM dbo.syain_health;
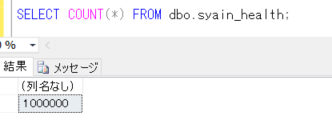
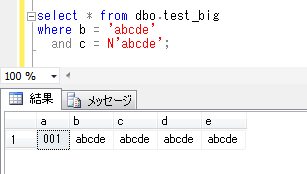
それでは、bmi の値が 20 ~ 25 の人の件数を確認します。
時間を計測するため、以下のコマンドを実行します。
SET STATISTICS TIME ON
SELECT COUNT(*) FROM dbo.syain_health
WHERE bmi BETWEEN 20 AND 25;
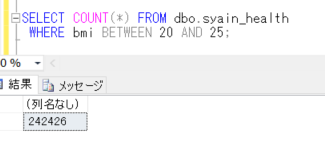
メッセージタブで表示されている時間は、
SQL Server 実行時間:
、CPU 時間 = 671 ミリ秒、経過時間 = 673 ミリ秒。
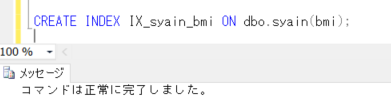
次に、インデックスを作成してみます。
CREATE INDEX IX_syain_bmi ON dbo.syain(bmi);
一度、データバッファキャッシュをクリアします。
DBCC DROPCLEANBUFFERS
再度、先ほどの処理を実行してみます。
SELECT COUNT(*) FROM dbo.syain_health
WHERE bmi BETWEEN 20 AND 25;
このときの時間を確認すると、
SQL Server 実行時間:
、CPU 時間 = 16 ミリ秒、経過時間 = 26 ミリ秒。
インデックスを作成することで、処理は速くなっていることが確認できました。
また、計算列は物理的にデータを保存することもできるということで、その場合には、テーブル作成時に、計算列の後ろにPRESISTED を付けます。
CREATE TABLE dbo.syain_health2(
id INT
,height DECIMAL(5,1)
,weight DECIMAL(5,1)
,bmi AS (
weight /(height/100 * height/100)) PERSISTED
,CONSTRAINT PK_syain_health2 PRIMARY KEY (id));
インデックスも追加します。
CREATE INDEX IX_syain_health_bmi2 ON dbo.syain_health2(bmi);
その後、同様にデータを100万件作成して、先ほどと同様のことを行ってみます。
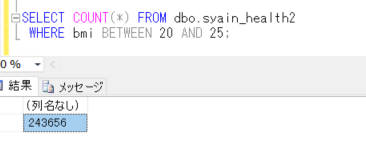
SQL Server 実行時間:
、CPU 時間 = 16 ミリ秒、経過時間 = 17 ミリ秒。
物理的にデータが保存されている場合とそうでない場合での処理時間の違いについては、それほど違いは無いようですが、多少速い感じでしょうか。
今日は以上まで
にほんブログ村