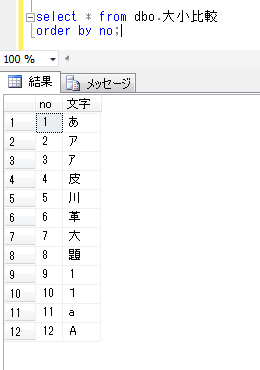
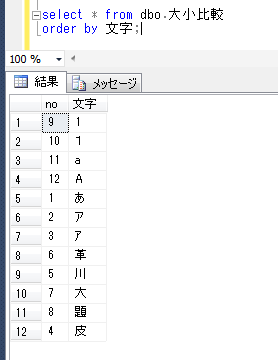
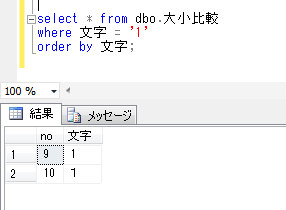
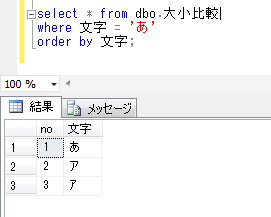
ITコーディネータのシュウです。

これは、昨年11月に島根の実家に帰省した際に、牡丹の花で有名な大根島の「由志園」でお土産に購入した牡丹の花を、父親が家の庭に植えていたものが、今年になって咲いたのを撮った写真です。綺麗に咲いたので、とても嬉しいですね。
現在、大根島は量、質ともに全国一の牡丹苗の生産地ということです。大根島は水田や農地が少なく養蚕と漁業以外に産業とよべるものはなかったそうですが、昭和30年代から島の女性達は家族を養うために全国へ牡丹などの苗木を売り歩く行商に出かけたそうです。島の女性達によって美しい牡丹の花は全国にたくさんのファンを作り、大根島の名前は牡丹の花とともに知られるようになりました。機会があれば、また「由志園」に行ってみたいと思います。
<本日の題材>
一時テーブル使用時の照合順序(SQL Server)
照合順序については、以前もブログで取り上げたことがありますが、最近、お客様の開発案件に携わる中で、一時テーブルを使ったSQLで照合順序に関するエラーが発生し、対応した経緯がありますので、ブログで取り上げてみたいと思います。
例)
以前ブログで取り上げた「照合順序(SQL Server)の異なるデータベース間のジョイン」と現象は同じことになりますが、SQL Serverの照合順序と、あるシステム用に作成したデータベースの照合順序が異なるときに、一時テーブルを利用し、かつ、データベース上のテーブルと一時テーブルをジョインするようなときに起きる現象になります。
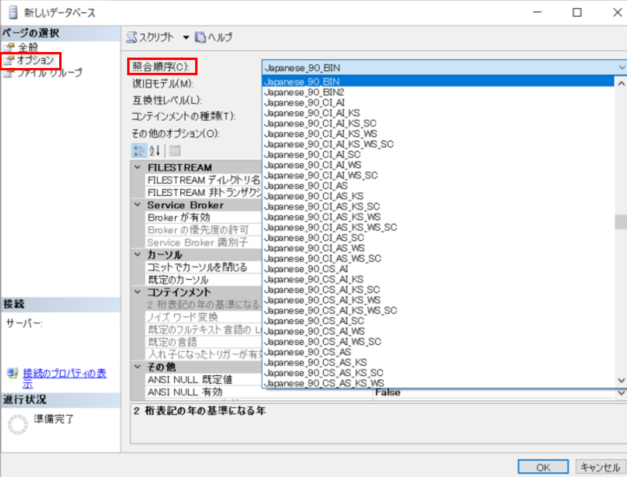
サーバーのプロパティで確認できる「サーバーの照合順序」は「Japanese_CI_AS」であるSQL Serverを使用するとします。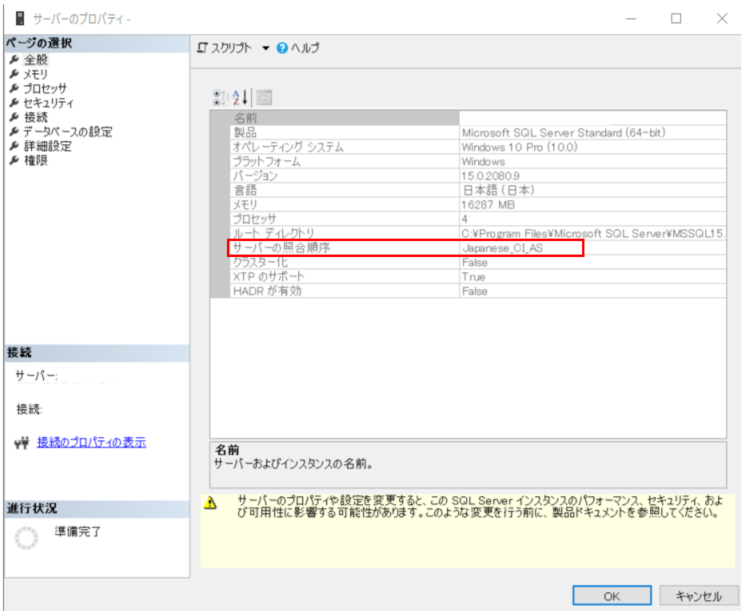
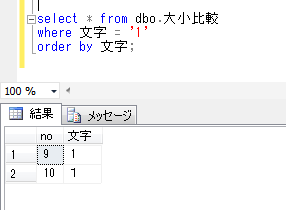
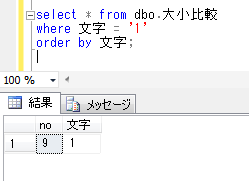
ここで、今回のシステムで使用する新しいデータベースの照合順序を、「Japanese_CS_AI_KS_WS」とします。(日本語で、大文字と小文字、ひらがなとカタカナ、全角と半角を区別する照合順序)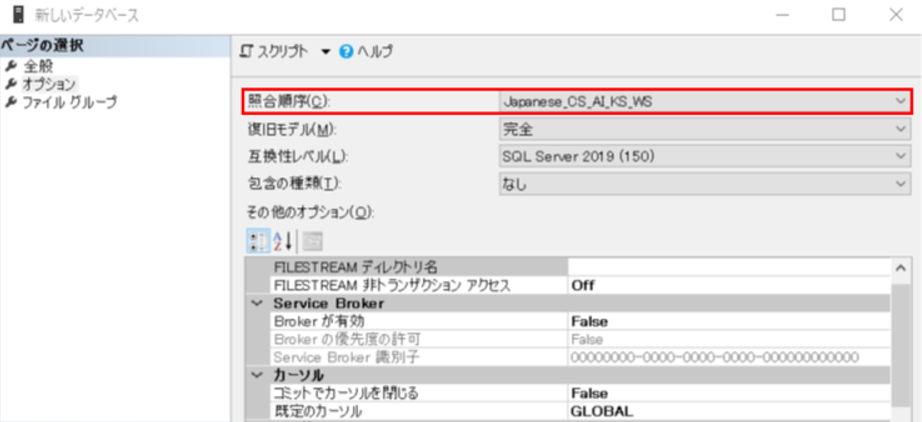
この環境で一時テーブルを作成した場合、一時テーブルは、システムデータベースの「tempdb」に作成されるため、一時テーブルの照合順序は「tempdb」の照合順序の設定「Japanese_CI_AS」に従って作成されます。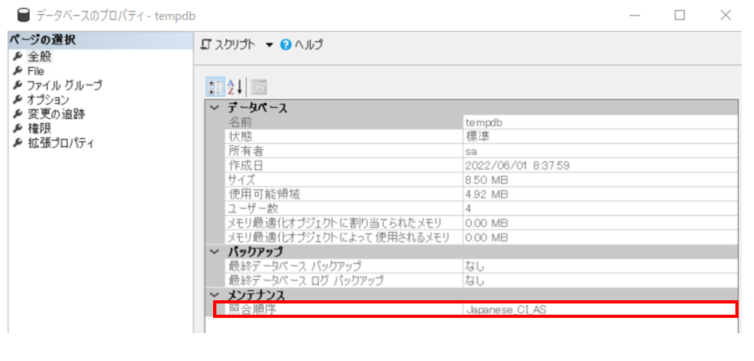
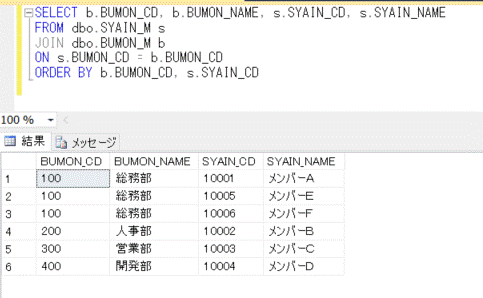
新しく作成したデータベースで、社員マスタと部門マスタを作成して、以下のようにJOINしてデータを抽出します。
SELECT b.BUMON_CD, b.BUMON_NAME, s.SYAIN_CD, s.SYAIN_NAME
FROM dbo.SYAIN_M s
JOIN dbo.BUMON_M b
ON s.BUMON_CD = b.BUMON_CD
ORDER BY b.BUMON_CD, s.SYAIN_CD;
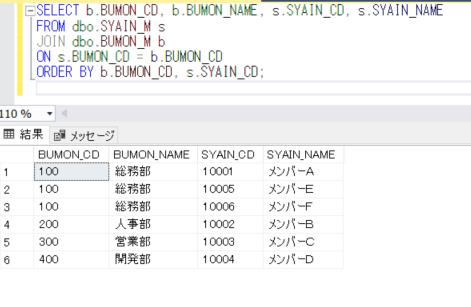
これを、部門マスタを一時テーブルに変更して実行してみます。
CREATE TABLE #bumon(
BUMON_CD varchar(3) NOT NULL,
BUMON_NAME varchar(20) NULL);
INSERT INTO #bumon
SELECT * FROM dbo.BUMON;
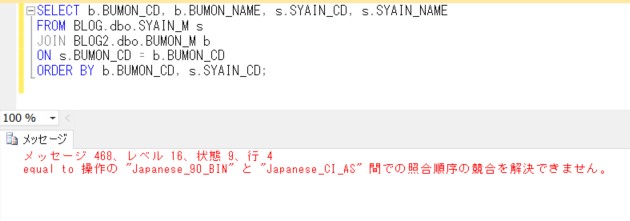
SELECT b.BUMON_CD, b.BUMON_NAME, s.SYAIN_CD, s.SYAIN_NAME
FROM dbo.SYAIN_M s
JOIN #bumon b
ON s.BUMON_CD = b.BUMON_CD
ORDER BY b.BUMON_CD, s.SYAIN_CD;
すると、下記のようなエラーが返ってきます。
「メッセージ 468、レベル 16、状態 9、行 13
equal to 操作の "Japanese_CI_AS" と "Japanese_CS_AI_KS_WS" 間での照合順序の競合を解決できません。」
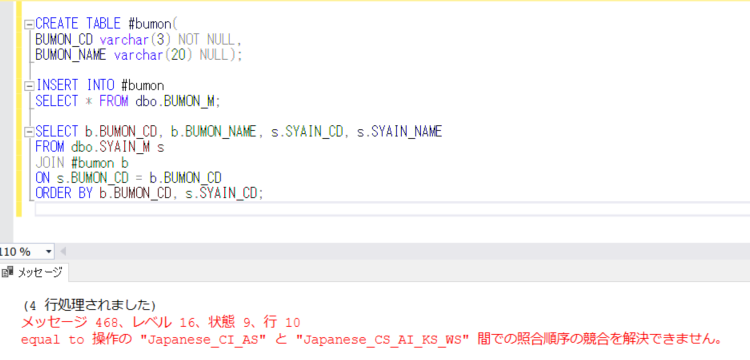
テーブルの存在するデータベースとtempdbデータベースの照合順序が異なるためにこのエラーが起きることが確認されました。
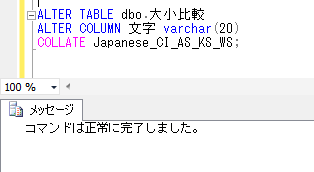
そのため、前回のブログでも取り上げたように、ジョインする項目にCOLLATE句を使用するか、一時テーブルを作成するときに、COLLATE句を設定することで、エラーを回避できます。
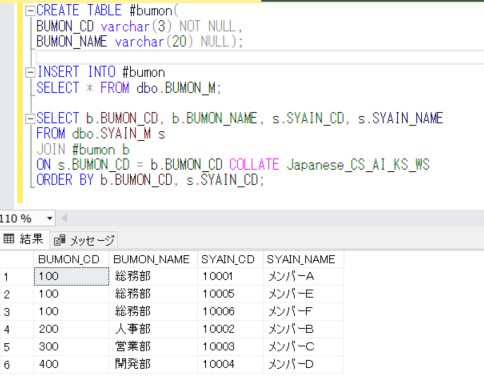
ジョインの際にCOLLATE句を使用する場合:
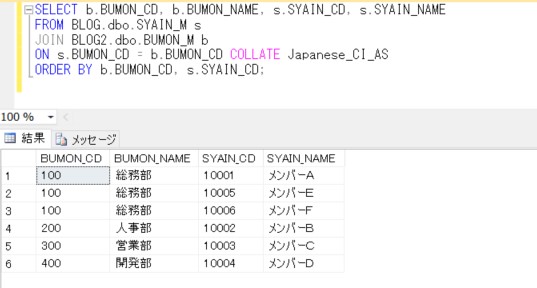
SELECT b.BUMON_CD, b.BUMON_NAME, s.SYAIN_CD, s.SYAIN_NAME
FROM dbo.SYAIN_M s
JOIN #bumon b
ON s.BUMON_CD = b.BUMON_CD COLLATE Japanese_CS_AI_KS_WS
ORDER BY b.BUMON_CD, s.SYAIN_CD;
一時テーブルを作成するときに、COLLATE句を使用する場合:
CREATE TABLE #bumon(
BUMON_CD varchar(3) COLLATE Japanese_CS_AI_KS_WS NOT NULL,
BUMON_NAME varchar(20) COLLATE Japanese_CS_AI_KS_WS NULL);
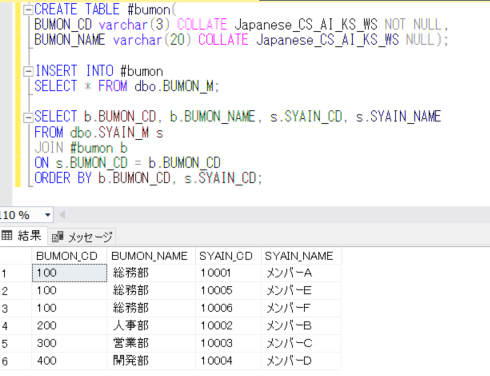
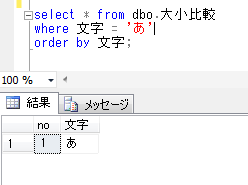
一時テーブルとのジョインでもエラーにならずに抽出できることが確認されました。使用するデータベースの照合順序を、SQL Serverの照合順序と異なるものを使用するときには、注意が必要ですね。
今日は以上まで
にほんブログ村