ITコーディネータのシュウです。

知人の方から、家に夏みかんの木があって、たくさん実がなるということで頂きました。その写真です。
さて、米国では、トランプ大統領が就任しましたが、就任直後から大統領令を連発し、大きな話題になるとともに、中にはきわめて大きな反発も起こっていますね。オバマケア見直し、TPPの離脱をはじめ、選挙のときから掲げてきた内容を具体的に実施しているわけですが、大きな波紋を呼んだものとしては、メキシコ国境の壁の建設、そして、中東・アフリカ7カ国からの渡航者の入国禁止(シリアからの難民受け入れの拒否も含む)です。
特に入国禁止については、米国政府内でも批判的な声が上がり、反対するデモも各地で起きていて、かなり混乱した状況ですね。この大統領令は憲法に違反しているということで、差し止めを命じるワシントン州の連邦地裁も現れました。強力な力を持つ大統領令ですが、司法のほうで歯止めをすることが可能だということが今回の内容で確認できました。さすが、民主主義の国!
しかし、おっかない世の中になってきました。これからどうなるのやら? できれば平和裏に進んでほしい。僕もやっぱり平和が好きですから。でもよく考えてみると、うちのかみさんもおっかなかったっけなあ?
<本日の題材>
PIVOT、UNPIVOT (SQL Server)
以前、複数行のデータを集計して横展開という記事をアップしたことがありましたが、今回はこれと同様のことを、SQL ServerのPIVOTという関係演算子を使って試してみたいと思います。
前回の記事では、部品別の日別の仕入数量のデータが、部品コード、年月日、数量というようなレイアウトでDBに登録されている場合に、部品別に、月を横に並べて仕入数量の月別合計値を表示させるようなケースについて、case文を使いながら各月を横に並べて表示させるようにしていました。
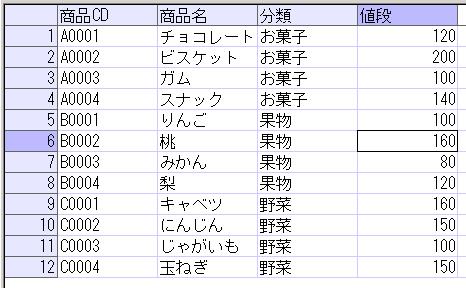
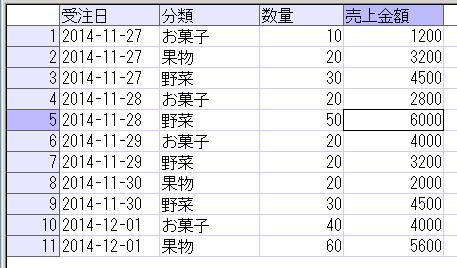
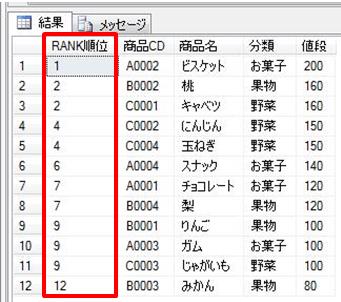
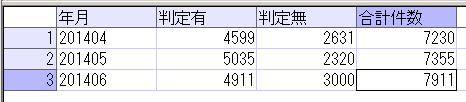
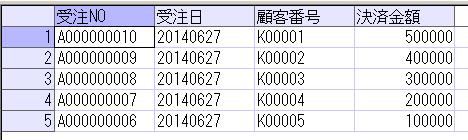
このテーブルのデータを単純に抽出すると以下のようになります。
SELECT * FROM dbo.部品発注表;
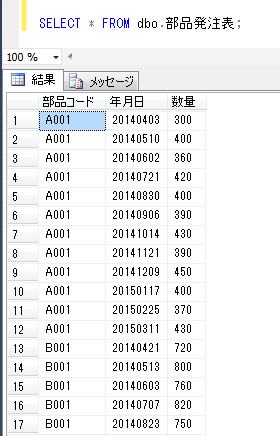
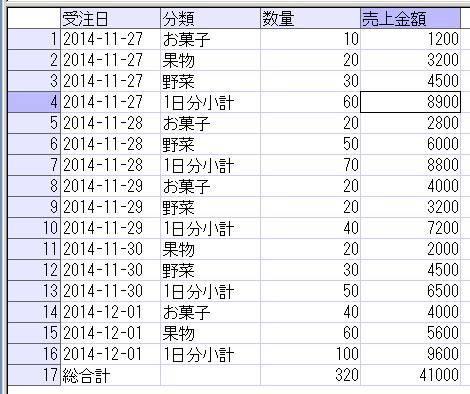
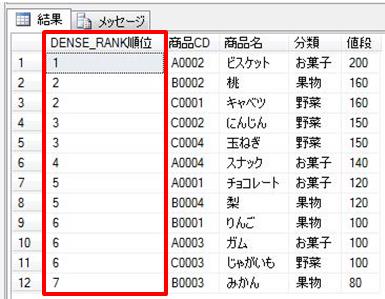
部品別に、月を横に並べて仕入数量の月別合計値を表示させることを、pivot演算子を使って試してみます。
SELECT *
FROM (select 部品コード, substring(年月日,5,2)+'月' as '月', 数量
from [dbo].[部品発注表]) as B_tab
PIVOT (
SUM(数量) FOR 月 IN
([01月], [02月], [03月], [04月], [05月], [06月], [07月], [08月], [09月], [10月], [11月], [12月])
) as PVTab
ORDER BY PVTab.部品コード;
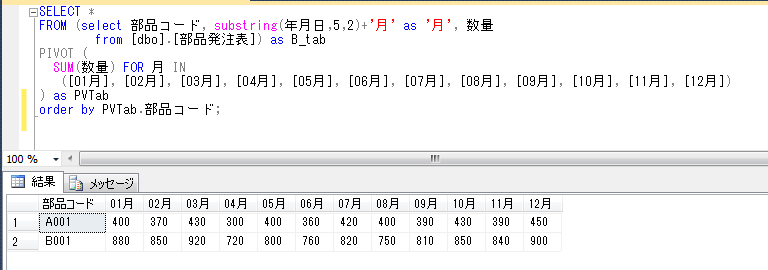
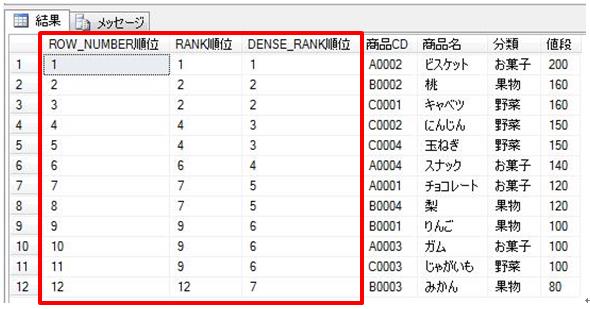
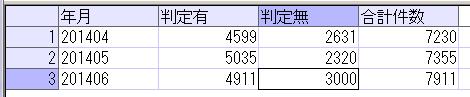
上記のSQLでは、FROM の後の集計対象テーブルの後に、PIVOT句を設定し、FOR .. IN で設定した値を列として出力して、それ毎にSUM関数で設定した項目[数量]を集計しています。なお、SUM関数とFOR .. IN で指定されていない「部品コード」でGROUP BYがされていて、それぞれの行が出力されています。最後のORDER BY句はオプションですが、並び順を設定できます。
Excelのピボットと同様のことが、SQLでできるのが確認できました。
また、以前別の記事「横に並んだ項目を縦の行データに変換」で、最初から列として登録されているデータを、複数行の縦のデータに変換して抽出するという件を取り上げましたが、UNPIVOT という関数がこれに該当します。
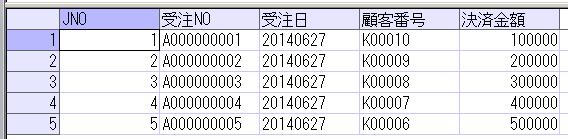
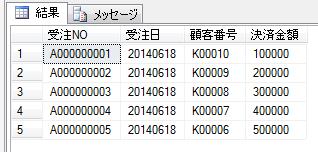
前回のデータをそのまま利用する場合に、まず、「商品売上」テーブルのデータをそのまま抽出すると、
SELECT * FROM dbo. 商品売上;
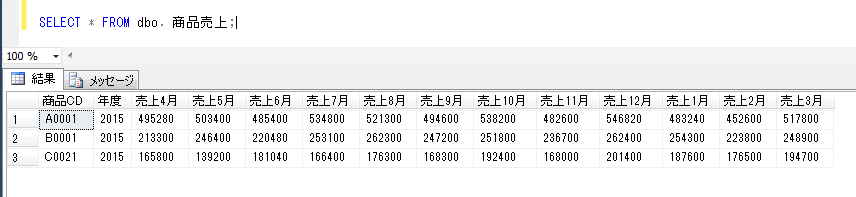
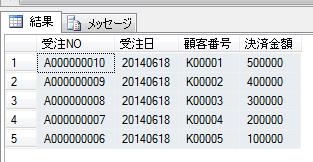
上記データについて、各月ごとのデータを行として表示する場合に、UNPIVOT演算子を使ったSQLは以下のようになります。
SELECT 商品CD, 月, 月売上
FROM
(SELECT * FROM dbo.商品売上) p
UNPIVOT
(月売上 FOR 月 IN
(売上4月, 売上5月, 売上6月, 売上7月, 売上8月, 売上9月, 売上10月, 売上11月, 売上12月, 売上1月, 売上2月, 売上3月)
)AS unpvt
ORDER BY unpvt.商品CD desc;
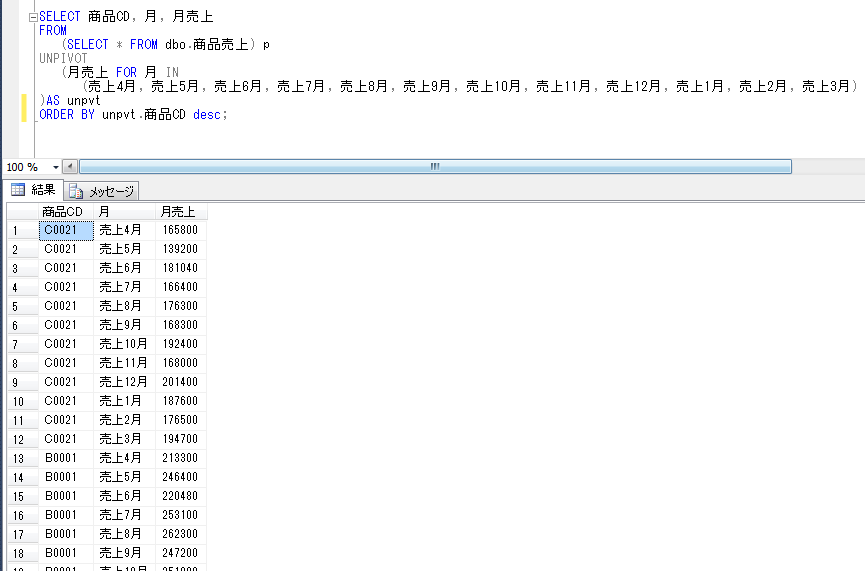
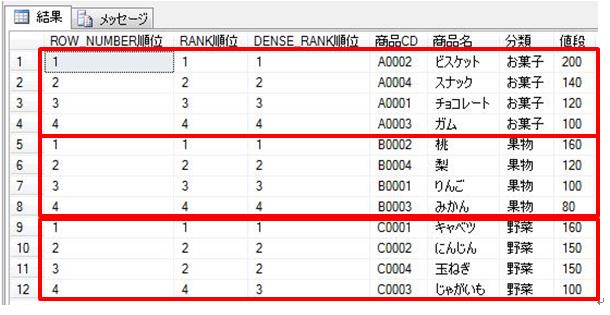
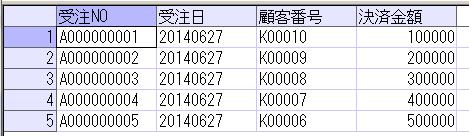
上記のSQLでは、FROM の後の対象テーブル(最初から横に並んだ項目を持つ)の後に、UNPIVOT句を設定し、FOR .. IN で設定した値を行として出力して、それ毎に月の売上を抽出しています。
また、FOR .. IN で指定されていない「商品CD」でGROUP BYがされていて、商品CD毎の、各月毎の売上が出力されています。
今日は以上まで
にほんブログ村









{kind=link}
{kind=link}
{kind=link}
{kind=link}