ITコーディネータのシュウです。

先日、ITCのポイント取得も兼ねて、≪MCPCモバイルソリューションフェア2014≫のセミナーに参加してきました。
http://www.mcpc-jp.org/fair2014/index.html
モバイル端末を業務で使用するケースが増えてきていますが、それに伴って紛失や盗難による情報漏洩のリスクも高まってきています。紛失した際にすぐに位置情報を確認し、端末をロックしたり、データを消去したり、消去したというレポートを受信できるようなサービスについての紹介のセミナーも数社行っていました。また、端末の電源が落ちていても、独自のBIOSによりリモートから操作することができるようにしているものも出てきていますね。お金目当てで盗難するケースも出てきている中、業務でモバイルを使うためには、このようなサービスが必要な時代であることを感じます。
<本日の題材>
WITH句と共通テーブル式(CTE)
標準SQL規格 SQL99 より、WITH句が導入されて、SELECT文の中で記述するインラインビュー(FROMの後に指定する問合せ)をWITH句で記述し、そのSQL文中に限り繰り返し使用できるようになりました。このWITH句に記述したものを「共通テーブル式」(CTE)といいます。
(OracleではOracle9iから対応、ただし、再帰WITH句はOracle11gR2から対応)
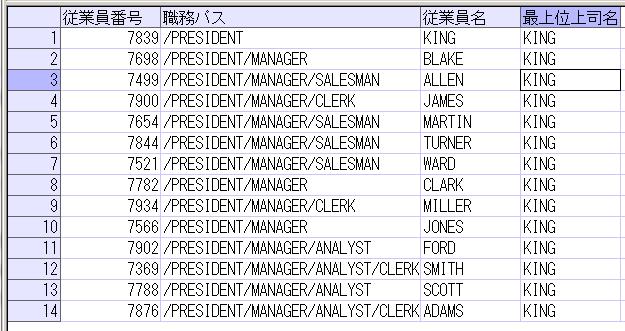
前回の階層構造のデータ表示(Oracle)で例として挙げたSQLの外部結合で使用している部分をWITH句で共通テーブル式を使うかたちにすると、以下のようになります。
WITH E2(EMPNO, ENAME) AS(
SELECT EMPNO, ENAME FROM EMP)
SELECT
E1.EMPNO AS 従業員番号
, E1.ENAME AS 従業員名
, LPAD(' ',(LEVEL-1)*2,' ')||E1.JOB AS 職務名
, E1.MGR AS 上司従業員番号
, E2.ENAME AS 上司従業員名
, LEVEL AS 階層LEVEL
FROM EMP E1
LEFT OUTER JOIN E2 ON E1.MGR = E2.EMPNO
START WITH E1.JOB = 'PRESIDENT'
CONNECT BY PRIOR E1.EMPNO = E1.MGR
ORDER SIBLINGS BY E1.ENAME;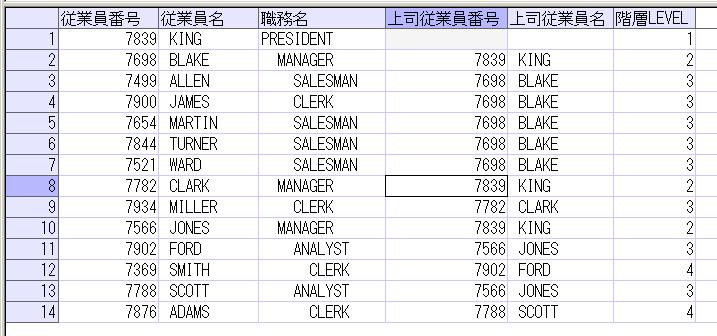
※結果は前回と同じになります。また、SQL自体も上から下に順に読めるので、わかりやすくなります。
次に、再帰WITH句についてですが、基本的な書き方は以下のようになります。
WITH 共通テーブル式(CTE)名(column1, column2, ...)
AS (
/* 元の SELECT文 */
UNION ALL
/* CTE名を参照する SELECT文 */
)
SELECT column_x1, column_x2, ... from CTE名;
例として、これもよく挙げられる例ではあると思いますが、1から20までの正の数を順に出力する場合のSQLです。
WITH RECUR_SEISU(val) AS (
SELECT 1 FROM DUAL
UNION ALL
SELECT val+1
FROM RECUR_SEISU
WHERE val+1 <= 20)
SELECT val FROM RECUR_SEISU;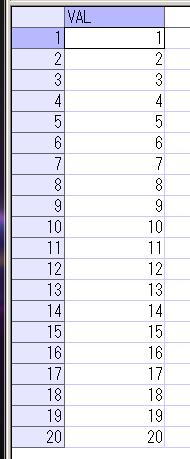
再帰WITH句で、最初にUNION ALLまでのSELECT文を実行して、その結果を使用してUNION ALLの下のSELECT文を実行し、条件を満たすあいだそれを繰り返して処理をしているのが確認できます。
SQL ServerではSQL Server2005から共通テーブル式を使用できるようになっています。
上記のSQLは下記のようになります。
WITH RECUR_SEISU(val) AS (
SELECT 1
UNION ALL
SELECT val+1
FROM RECUR_SEISU
WHERE val+1 <= 20)
SELECT val FROM RECUR_SEISU;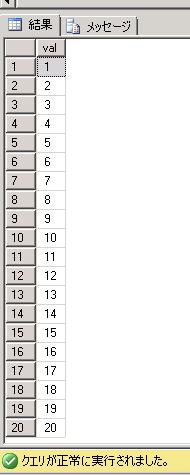
※結果は同じです。
ちなみに、MySQLでは、WITH句を使っての共通テーブル式についてはまだ未対応のようです。
今日は以上まで
にほんブログ村













{kind=link}