ITコーディネータのシュウです。

紅葉が好きなので、今回も紅葉の写真をアップしました。皆さんはどうですか?
先日、ITコーディネータのイノベーション経営セミナーに参加した時に、あるコンピュータメーカ:F社の方が、ハッカソン、アイデアソンについての取り組みを説明をされていました。そこではさくらで東北地方を元気にしようということで、いろんな立場の違う方たちが短期集中的に意見を出し合って、アイデアを作り上げたという内容でした。確かにある会社だけで考えるよりは、素晴らしいアイデアが作れそうな気がしますね。画期的な取り組みだと感じました。
ファシリテーションを如何にうまくやれるかとか、実際にサービスに結び付けるところまで持って行けるのかとか、いろいろやる上では課題もありそうにも思えますが、今後はこういう「共創」ということもより増えて行きそうですね。
<本日の題材>
再帰SQL
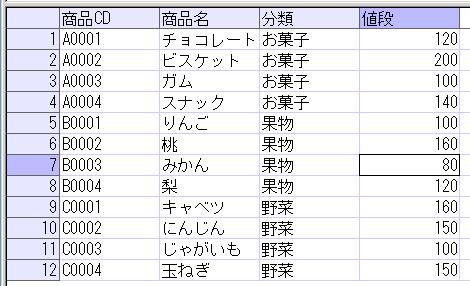
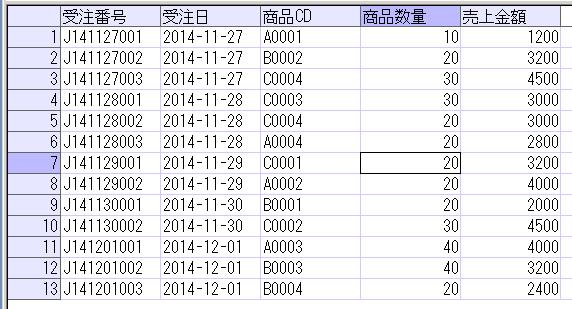
前々回、前回の続きで、階層構造のデータの表示を、再帰SQLを使用して行うという内容を取り上げたいと思います。階層構造のデータとして、部署データを使います。
CREATE TABLE 部署マスタ(
部署NO VARCHAR2(5)
, 部署名 VARCHAR2(40)
, 親部署NO VARCHAR2(5)
, CONSTRAINT PK_部署マスタ PRIMARY KEY (部署NO));
INSERT INTO 部署マスタ VALUES('10000', '人事総務部', null);
INSERT INTO 部署マスタ VALUES('20000', '経理部', null);
INSERT INTO 部署マスタ VALUES('30000', '開発企画部', null);
INSERT INTO 部署マスタ VALUES('40000', '営業部', null);
INSERT INTO 部署マスタ VALUES('11000', '人事課', '10000');
INSERT INTO 部署マスタ VALUES('12000', '総務課', '10000');
INSERT INTO 部署マスタ VALUES('13000', '教育課', '10000');
INSERT INTO 部署マスタ VALUES('21000', '経理課', '20000');
INSERT INTO 部署マスタ VALUES('31000', '企画課', '30000');
INSERT INTO 部署マスタ VALUES('32000', '開発課', '30000');
INSERT INTO 部署マスタ VALUES('33000', 'システム課', '30000');
INSERT INTO 部署マスタ VALUES('41000', '第一営業課', '40000');
INSERT INTO 部署マスタ VALUES('42000', '第二営業課', '40000');
INSERT INTO 部署マスタ VALUES('32100', '基礎研究グループ', '32000');
INSERT INTO 部署マスタ VALUES('32200', '商品開発グループ', '32000');
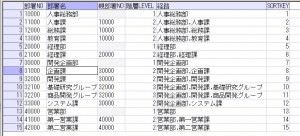
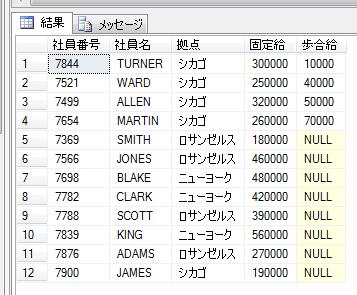
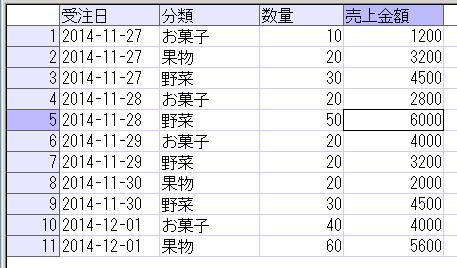
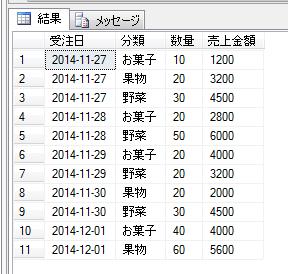
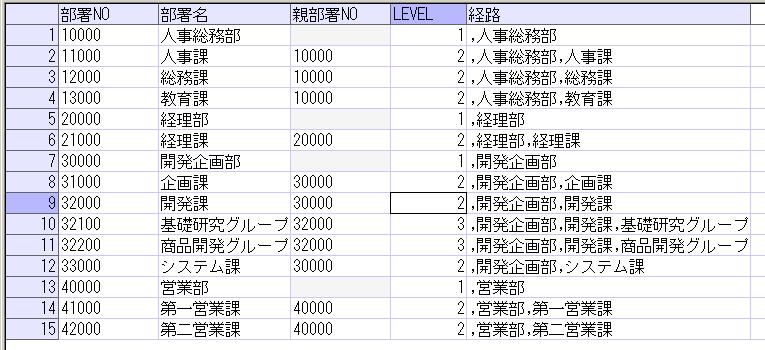
この部署マスタの階層情報を、START WITH句、及びCONNECT BY句を使用したSQLで検索すると、以下のようになります。
SELECT 部署NO, 部署名, 親部署NO,
LEVEL, SYS_CONNECT_BY_PATH(部署名,',') AS 経路
FROM 部署マスタ
START WITH 親部署NO IS NULL
CONNECT BY PRIOR 部署NO = 親部署NO
ORDER SIBLINGS BY 部署NO;
結果は以下です。

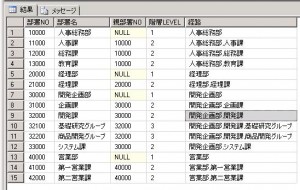
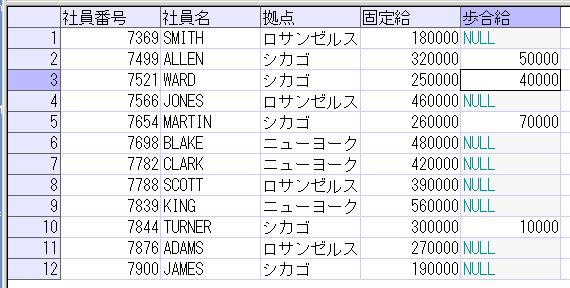
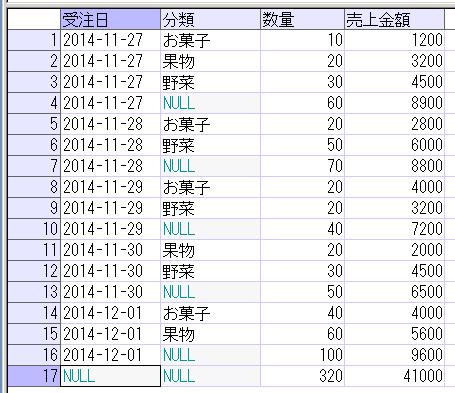
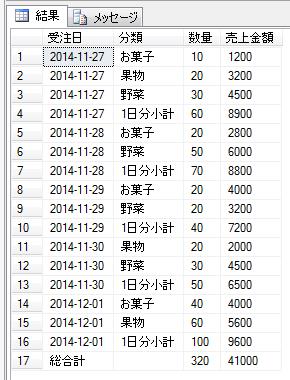
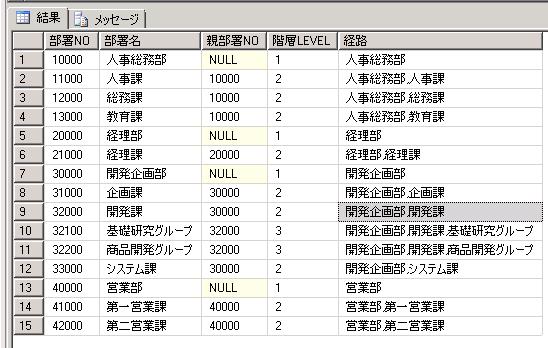
これを、再帰WITH句を使った再帰SQLで表現すると以下のようになります。
WITH REC_BUSYO(部署NO, 部署名, 親部署NO, 階層LEVEL, 経路) AS(
SELECT 部署NO, 部署名, 親部署NO, 1, 部署名
FROM 部署マスタ
WHERE 親部署NO IS NULL
UNION ALL
SELECT b.部署NO, b.部署名, b.親部署NO,
a.階層LEVEL+1, a.経路 || ',' || b.部署名
FROM REC_BUSYO a, 部署マスタ b
WHERE a.部署NO = b.親部署NO)
SEARCH DEPTH FIRST BY 部署NO SET Sortkey
SELECT * FROM REC_BUSYO;
結果は以下です。
WHERE のa.部署NO = b.親部署NOで、PRIOR 部署NO = 親部署NO の部分を代わりに表し、SEARCH DEPTH FIRST BYのSERCH句を使って深さ優先探索(探索対象となる木の最初のノードから、目的のノードが見つかるか子のないノードに行き着くまで、深く伸びていく探索)順にソートすることで、ORDER SIBLINGS BYの階層順序を壊さずにソートすることを代用しています。
SQL Serverでも同様のことを再帰SQLで試してみました。
WITH REC_BUSYO(部署NO,部署名,親部署NO,階層LEVEL,経路) AS(
SELECT
部署NO, 部署名 ,親部署NO
, 1, CAST(部署名 AS NVARCHAR(4000)) AS 経路
FROM 部署マスタ
WHERE 親部署NO IS NULL
UNION ALL
SELECT
b.部署NO, b.部署名, b.親部署NO
, a.階層LEVEL+1, a.経路 + N',' + b.部署名
FROM REC_BUSYO a, 部署マスタ b
WHERE a.部署NO = b.親部署NO)
SELECT * FROM REC_BUSYO
ORDER BY 部署NO;
※経路のところで、CASTでNVARCHAR(4000) に変換しないでそのままで実行すると、
メッセージ240、レベル16、状態1、行1
再帰クエリ"REC_BUSYO" の列"経路" で、アンカーの型と再帰部分の型が一致していません。
のようなエラーが出ました。
今日は以上まで
 にほんブログ村
にほんブログ村








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}