ITコーディネータのシュウです。

先日、妻の知人の誘いで、埼玉県日高市のほうで行われた、馬射戲(マサヒ)騎射競技大会、それから高麗神社に行ってきました。馬射戲(マサヒ)というのは、高句麗古墳壁画の世界を再現した騎射競技ということで、日本の流鏑馬(やぶさめ)のルーツではないかと言われているようです。上の写真は、馬上から射た弓が的に的中して、まさに的が割れたところを撮った写真です。
埼玉県の日高市、飯能市の辺りは、716年に建郡された高麗郡といわれた地域であり、来年2016年が、建郡1300年ということで、いろいろな記念事業が行われていくようです。
実は、歴史やルーツというものが結構好きな私は、今回高麗(こま)神社も初めて行ってきたのですが、歴史を感じるとともに、埼玉県というのは渡来人とのつながりが深い地域だということを改めて知った1日でした。久しぶりに妻と一緒に歩いたのも、昔に戻ったようでうれしかったですね!
<本日の題材>
ストアド・ファンクション
今まで、何度かストアド・プロシージャを使用するような例を上げたことがありますが、ストアド・ファンクションについてはあまり取り上げて来なかったと思いますので、今回、題材に上げてみたいと思います。
ファンクションは、処理後に計算結果を1つだけ戻すもので、戻り値を持っています。戻り値は、Oracleの場合はRETURN句、SQL Serverの場合はRETURNS句でデータ型を設定します。戻す値については、ORACLE、SQL Serverともに、BEGIN ~ ENDで囲まれる部分の中でRETURN文によって設定します。
なお、プロシージャの場合は、引数でOUTパラメータを設定することで、複数の値を戻すことができますが、それは引数であって戻り値ではないということです。
また、プロシージャの場合は、CALL文やEXEC文で実行しますが、ファンクションの場合は、通常のSQLのSELECT文に直接記述して結果を得ることができます。
SELECT ファンクション名(xx) … FROM …
例1)
あるシステムで、年ごとに、いつからいつまでが第何週かを独自に設定している「WEEKマスタ」というものを準備し、指定した日付が第何週目かを確認するファンクションを作成します。
SQL Serverの場合:
テーブルの定義は、
CREATE TABLE [dbo].[WEEKマスタ](
[年] [decimal](4, 0) NOT NULL,
[WEEK] [decimal](2, 0) NOT NULL,
[開始日] [date] NOT NULL,
[終了日] [date] NOT NULL,
CONSTRAINT [PK_WEEKマスタ] PRIMARY KEY CLUSTERED ([年] ASC,[WEEK] ASC)
/
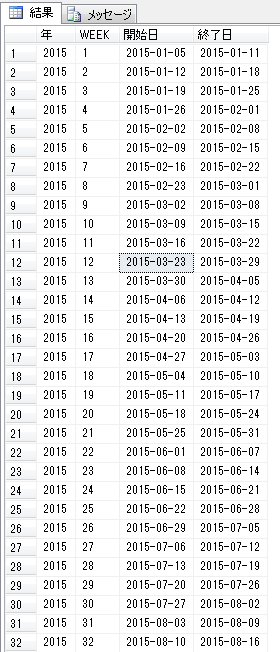
データを確認すると、
SELECT年, WEEK, 開始日,終了日
FROM dbo.WEEKマスタ
ORDER BY 年, WEEK;
ファンクションは例えば以下のようになります。
CREATE FUNCTION dbo.USF001_WEEK取得(
@P年月日 DATE
) RETURNS DECIMAL(2,0)
AS
BEGIN
DECLARE @WEEK DECIMAL(2,0) = 0;
SELECT @WEEK = WEEK
FROM dbo.WEEKマスタ
WHERE @P年月日 BETWEEN開始日 AND終了日;
RETURN @WEEK
END;
GO
実際にこのファンクションを使って、指定した日付が第何週になるかを確認してみます。
SELECT dbo.USF001_WEEK取得('2015-11-16')

46週めという結果が出ました。
これを、Oracleで同じように試してみます。
テーブル定義は、
CREATE TABLE WEEKマスタ(
年 NUMBER(4) NOT NULL,
WEEK NUMBER(2) NOT NULL,
開始日 DATE NOT NULL,
終了日 DATE NOT NULL,
CONSTRAINT PK_WEEKマスタ PRIMARY KEY(年, WEEK));
ファンクションは先ほどと同様にすると、以下のようにできます。
CREATE OR REPLACE FUNCTION WEEK取得(P_年月日 IN DATE)
RETURN NUMBER
AS
V_WEEK DECIMAL(2,0) := 0;
BEGIN
SELECT WEEK INTO V_WEEK
FROM WEEKマスタ
WHERE P_年月日 BETWEEN 開始日 AND 終了日;
RETURN V_WEEK;
END;
/
このファンクションをSELECT文の中で使用して、WEEKを取得すると
SELECT WEEK取得('2015-11-16') FROM DUAL;
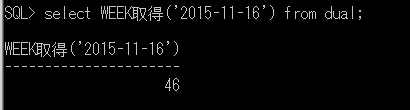
結果は先ほどと同じく46週めですね。
例2)
メタボの予防などで、肥満度の話が出てきますが、その肥満度をチェックするのに、BMI(肥満指数)というものを用いることが多いと思います。今回は、その肥満指数BMIの計算をファンクションで実行してみたいと思います。
ファンクションは以下のようにできます。(SQL Server)
CREATE FUNCTION dbo.BMI取得(
@体重 DECIMAL(5,2)
,@身長 DECIMAL(5,2)
) RETURNS DECIMAL(7,5)
AS
BEGIN
DECLARE @BMI DECIMAL(7,5) = 0;
SELECT @BMI = @体重 /(@身長/100 * @身長/100);
RETURN @BMI
END;
GO
実際に試してみると、体重:61.0kg、身長:165.5cmの場合
SELECT dbo.BMI取得(61.0, 165.5)

結果は、22.27070 ということで、肥満度は普通ということですね。
調べてみると、BMI指数の値によって、以下のように言われているようです。
・18.5未満 =痩せ
・18.5~25=普通
・25~30 =肥満レベル1
・30~35 =肥満レベル2
・35~40 =肥満レベル3
・40~ =肥満レベル4
試しに、知人の値を確認してみます。
SELECT dbo.BMI取得(82.0, 164.0)
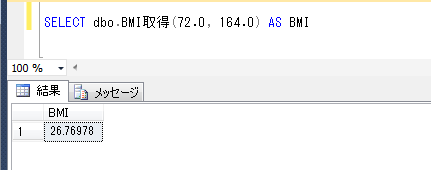
BMI指数が30を超えているので、肥満レベル2ですね。生活習慣病には是非気を付けてほしいものです。
ちなみに、ORACLEでも同様のファンクションを作成すると、以下のようになります。
CREATE OR REPLACE FUNCTION BMI取得 (P_体重 NUMBER, P_身長 NUMBER)
RETURN NUMBER
AS
V_BMI NUMBER(7,5) := 0;
BEGIN
SELECT P_体重 / (P_身長/100 * P_身長/100) INTO V_BMI
FROM DUAL;
RETURN V_BMI;
END;
/
実行してみると、
SELECT BMI取得(61.0, 165.5) AS BMI FROM DUAL;
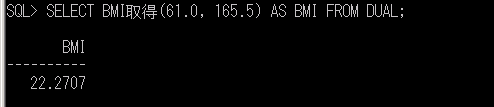
結果はSQL Serverのときと同じ値が出ました。
今日は以上まで
にほんブログ村