ITコーディネータのシュウです。

5月もあと2日になりました。あっという間に日が過ぎて行きますね。今年もG/Wのときに、加須市の玉敷神社の藤まつりに行って来ました。上記はその写真です。たまに家族みんなで出かけるのもいいものです。
そう言えば、車に乗っているときに、家内が道端にきれいに咲いていた芝桜があったらしく、きれいね~と言ったので、桜ということで、思わず空のほうを見て桜を探してしまったところ、また笑われてしまいました。
芝桜と言えば、日本各地にきれいで有名なところはあると思いますが、宮崎県新富町に、目の見えなくなってしまった奥様に笑顔を取り戻したいということで、20年以上かけて庭に一面のピンクの芝桜を育てた黒木さんという方の庭の芝桜がきれいだということで有名みたいですね。フジテレビのMr.サンデーという番組でも放送され、とても感動的で反響が多かったそうです。黒木さんは毎年芝桜のシーズンになるとご自宅の庭をボランティアで開放、オープンガーデンとし、連日多くの見物客に花を楽しませてくださっておられるとのことです。そこに込められた夫婦愛が素晴らしいですね。そのように妻を愛せる夫になりたいものです。
http://www.pmiyazaki.com/etc/sibazakura/
ただ、一面に広がるシバザクラを皆さんに開放するのは、今年(2017年)で最後となるとのことです。芝桜の手入れはとても大変なようで、ご高齢ということもあり、残念ですが、本当に長い間お疲れ様でした。
さて、dbSheetClientに新しい事例がまたアップされています。dbSheetClientを使って全社をカバーする「予算実績管理システム」を構築! SAP(ERP)システムとのデータ連携も実現!ということで、クレスコ・イー・ソリューション株式会社様の事例です。興味のある方は以下をご参照ください。
http://www.newcom07.jp/dbsheetclient/usrvoice/cresco_esol.html
<本日の題材>
バルク処理(Oracle)
OracleでPL/SQLを使って、ループの処理を行うことはよくあることだと思います。そのループ文などのPL/SQLプログラムは、内部的にはSQLエンジンとPL/SQLエンジンの2つのエンジンが、それぞれSQL文とPL/SQL文の処理を担当して実行するため、ループの回数分エンジンの切替が発生しています。この制御の移行はコンテキスト・スイッチと呼ばれ、その都度オーバーヘッドが発生して、パフォーマンスが低下することになります。
このようなオーバーヘッドを削減できる機能として、バルク処理というものがあり、エンジンの切替を最小限に抑えることができるということです。今回は、このバルク処理について取り上げてみたいと思います。
例)
顧客マスタを作成し、そこに20万件の顧客データをテスト的に作成してみたいと思います。それを、今回は FOR LOOP文で作成してみますが、その際に、普通にLOOP処理を行うのと、バルク処理を行うので、処理時間も比較して見ます。
まず、顧客マスタテーブルを作成します。
CREATE TABLE customer(
c_id number(8)
,c_name varchar2(20)
,Constraint PK_customere Primary key(c_id));
次に、FOR LOOP文で、テストデータを作成します。
BEGIN
FOR i IN 1..200000 LOOP
INSERT INTO customer(c_id, c_name) VALUES(i, '顧客名_'||LPAD(TO_CHAR(i),8,'0'));
END LOOP;
END;
/
今回は、処理時間を測定したいので、sqlplus 上で以下を実行してから、上記の処理を実行します。
SET TIMING ON

処理に8.25秒かかっていますね。データを念のため確認してみます。
SELECT * FROM customer
ORDER BY c_id;
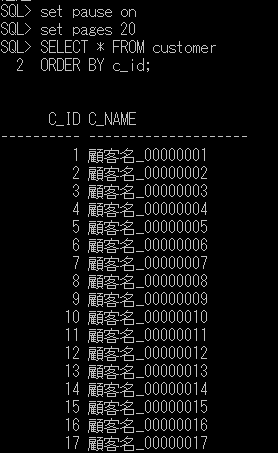
データが登録されていることが確認できます。
このようなINSERTの処理を、バルク処理で行う場合、FORALL文を指定して実行します。
DECLARE -- ①
TYPE c_id_t IS TABLE OF customer.c_id%TYPE
INDEX BY PLS_INTEGER;
c_id c_id_t;
TYPE c_name_t IS TABLE OF customer.c_name%TYPE
INDEX BY PLS_INTEGER;
c_name c_name_t;
BEGIN
FOR i IN 1..200000 LOOP -- ②
c_id(i) := i;
c_name(i) := '顧客名_'||LPAD(TO_CHAR(i),8,'0');
END LOOP;
FORALL j IN 1..200000
INSERT INTO customer(c_id, c_name) VALUES(c_id(j), c_name(j)); -- ③
END;
/
まず、①宣言部で、TABLE型のコレクション c_id, c_name を定義します。ここで、コレクション変数とは、同じデータ型の値を複数格納できる変数のことです。そして、②のFOR LOOP文でそのコレクションに200000行を代入します。その後、③のINSERT文のVALUES句にこのコレクションを指定し、200000行のデータを customer表に一括挿入します。このとき、DML分の直前に FORALL文を指定します。
構文は以下:
FORALL <索引名> IN <下限値>..<上限値> <DML文>
この処理では、INSERT文はSQLエンジンで一度に処理できるため、エンジンの切替は1回で済むことになり、高速化されます。
実際に試してみようと思いますが、データを削除した後、パフォーマンスの比較を正確に行いたいので、一旦メモリをフラッシュします。
truncate table customer;
connect / as sysdba
ALTER SYSTEM FLUSH BUFFER_CACHE;
上記のpl/sqlを実行します。
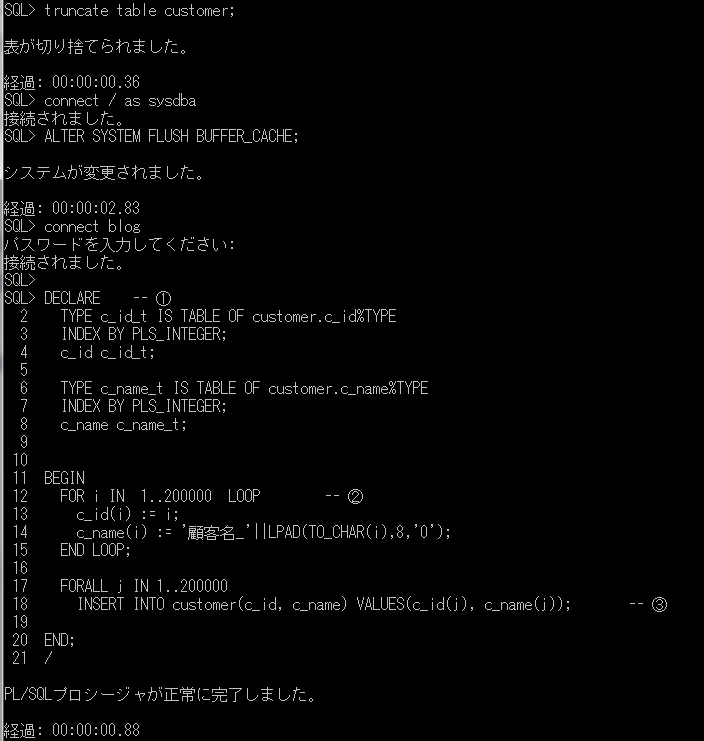
通常のLOOP処理で8.25秒かかっていた20万件の登録処理が、0.88秒で終わったことが確認できます。
SELECT * FROM customer
ORDER BY c_id;
SELECT COUNT(*) FROM customer;
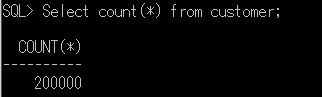
データが確かに20万件登録されているのが確認できます。
バルク処理を行うことで、処理はかなり高速化されることがわかりますね。
今日は以上まで
にほんブログ村