ITコーディネータのシュウです。

今月27日に再び発生した大規模なサイバー攻撃によって、世界各地で被害が出ています。今回のランサムウェアは専門家の間で「Petya」と呼ばれるウイルスが使われたとみられているそうです。WannaCryと同様に、WindowsのSMB(Server Message Block)の脆弱性(通称Eternal Blue)を利用しているとのことで、対策としては、Windowsを常に最新の状態にすること、アンチウィルスソフトウェアを最新のものにしておくこと、さらにメールにあるURLをクリックする際には十分な注意が必要ですね。また、いざというときにバックアップを取ることも推奨されています。
IPA独立行政法人情報処理推進機構セキュリティセンターが出している「情報セキュリティ10大脅威 2017」でも、個人向け、組織向けともに、ランサムウェアによる被害が2位に入っていますね。組織向けの1位は、こちらもよく話題になる標的型攻撃による情報流出です。様々な情報を扱う企業としては、社員への教育を含め様々なリスクを考慮した対策が必要ですね。
本当に、いつも危険と隣り合わせていることを自覚しながらPCを使わないといけない時代になってきたと感じます。
さて、dbSheetClientに新しい事例がまたアップされています。
dbSheetClientで内製化を実現、MS-Accessで開発した『総合管理システム』をdbSheetClientでWeb化し、抱えていた課題を全てクリア !!ということで、綜合エナジー株式会社様の事例です。
興味のある方は以下をご参照ください。
http://www.newcom07.jp/dbsheetclient/usrvoice/sogo_energy.html
<本日の題材>
ビットマップインデックス(Oracle)
Oracleで検索の性能を向上するためにインデックスを作成しますが、データウェアハウスなどを構築した際には、カーディナリティの値が低い(取りうる値が限られている)列に対しては、ビットマップインデックスを作成することで効果があるという話しを聞くことがよくありますが、今回、それを試してみたいと思います。
例)
性別、血液型などのような取りうる値が限られている列を持つ顧客マスタを作成し、そこに300万件の顧客データをテスト的に作成してみたいと思います。前回題材に上げたバルク処理を使って、データの登録処理時間を短縮したいと思います。
まず、顧客マスタテーブルを作成します。
CREATE TABLE t_customer(
c_id number(7)
,c_gender varchar2(4) -- 性別
,c_blood_type varchar2(2) -- 血液型
,c_age number(3) -- 年齢
,constraint PK_t_customer Primary key (c_id));
次に、前回題材として取り上げたバルク処理を使って、テストデータを作成してみます。
DECLARE
TYPE c_id_t IS TABLE OF t_customer.c_id%TYPE
INDEX BY PLS_INTEGER;
c_id c_id_t;
TYPE c_gender_t IS TABLE OF t_customer.c_gender%TYPE
INDEX BY PLS_INTEGER;
c_gender c_gender_t;
TYPE c_blood_type_t IS TABLE OF t_customer.c_blood_type%TYPE
INDEX BY PLS_INTEGER;
c_blood_type c_blood_type_t;
TYPE c_age_t IS TABLE OF t_customer.c_age%TYPE
INDEX BY PLS_INTEGER;
c_age c_age_t;
BEGIN
FOR i IN 1..3000000 LOOP
c_id(i) := i;
c_gender(i) := CASE mod(c_id(i), 3) WHEN 0 THEN '男性' WHEN 1 THEN '女性' ELSE null END;
c_blood_type (i) := CASE mod(c_id(i), 5) WHEN 0 THEN 'A' WHEN 1 THEN 'B' WHEN 2 THEN 'O' WHEN 3 THEN 'AB' ELSE null END;
c_age(i) := 20+mod(c_id(i), 50);
END LOOP;
FORALL j IN 1..3000000
INSERT INTO t_customer(c_id, c_gender, c_blood_type, c_age) VALUES(c_id(j), c_gender(j), c_blood_type(j), c_age(j));
END;
/
今回も、処理時間を測定したいので、sqlplus 上で以下を実行してから、上記の処理を実行します。
SET TIMING ON
上記のpl/sqlを実行します。
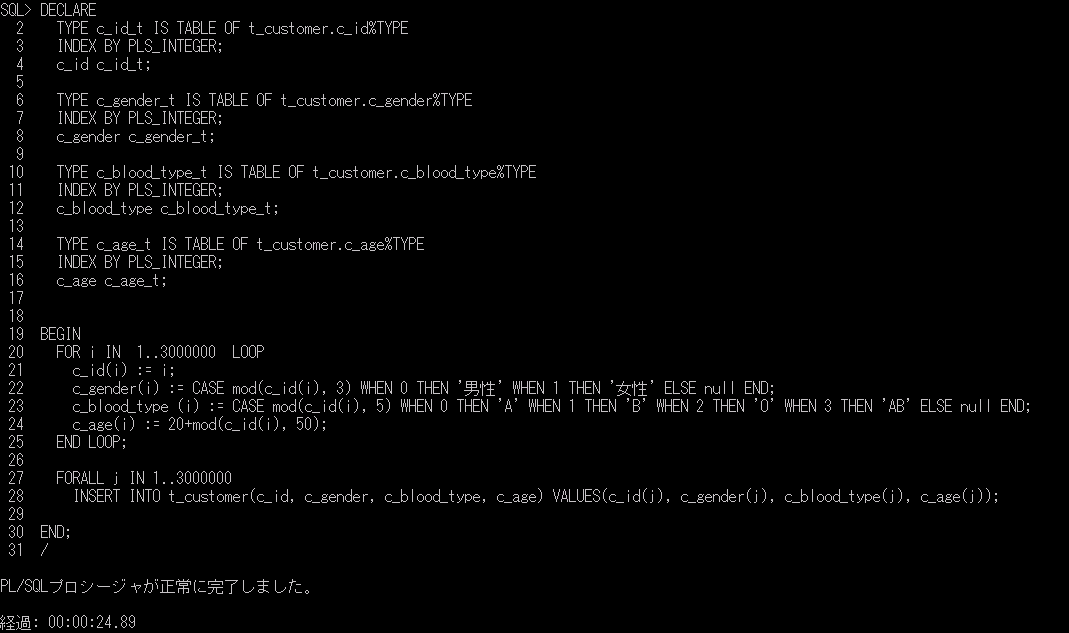
24.89秒で処理が終了しています。これを、通常のLOOP処理で実行すると、3分22秒程度時間がかかりましたので、やはりバルク処理が有効だということを改めて確認しました。
データを確認してみます。
SELECT * FROM t_customer
ORDER BY c_id;
件数も確認してみます。
Select count(*) from t_customer;
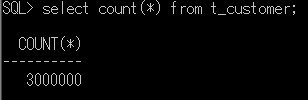
データが確かに300万件登録されているのが確認できます。
この t_customer テーブルのデータの中に、男性以外(NULLデータも含む)で、血液型が「A」型と「B」型の人が何人いるかを抽出してみます。そのときも実行計画も合わせて表示させてみます。
set autotrace on
select count(*) from t_customer
where c_gender <> '男性'
and c_blood_type in ('A','B');
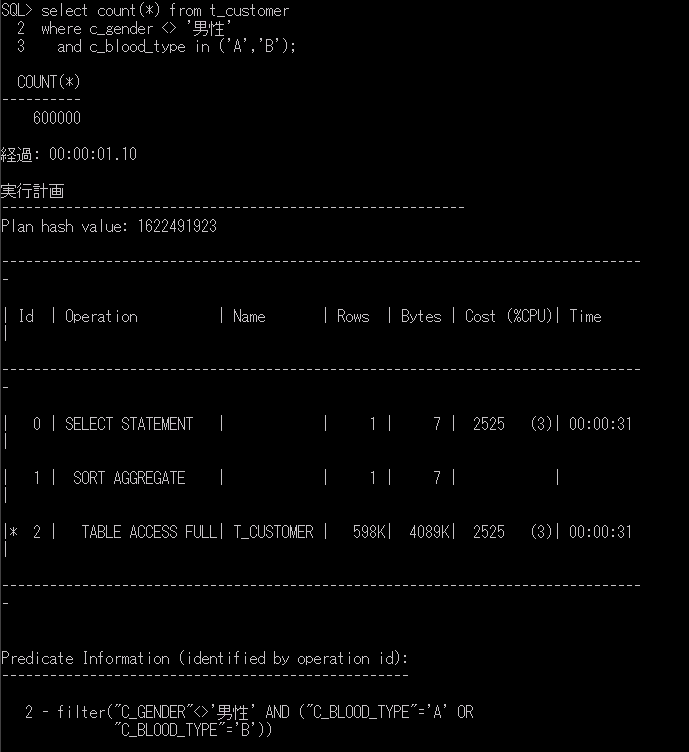
実行計画を見ると、t_customerテーブルを「TABLE ACCESS FULL」で全レコードにアクセス(フルスキャン)して該当レコードの件数を確認していることがわかります。
この t_customer テーブルの性別、血液型項目に通常のインデックスを作成してみます。
CREATE INDEX cust_idx2 ON t_customer (c_gender);
CREATE INDEX cust_idx3 ON t_customer (c_age);
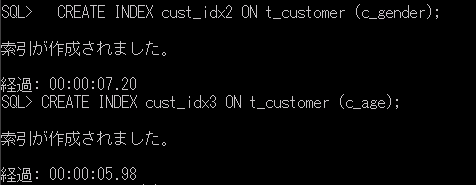
それぞれ、7.2秒、5.98秒と、多少時間がかかることがわかります。
この状態で、再度先ほどの男性以外で、血液型が「A」型と「B」型の人が何人いるかを、同じSQLで実行してみます。
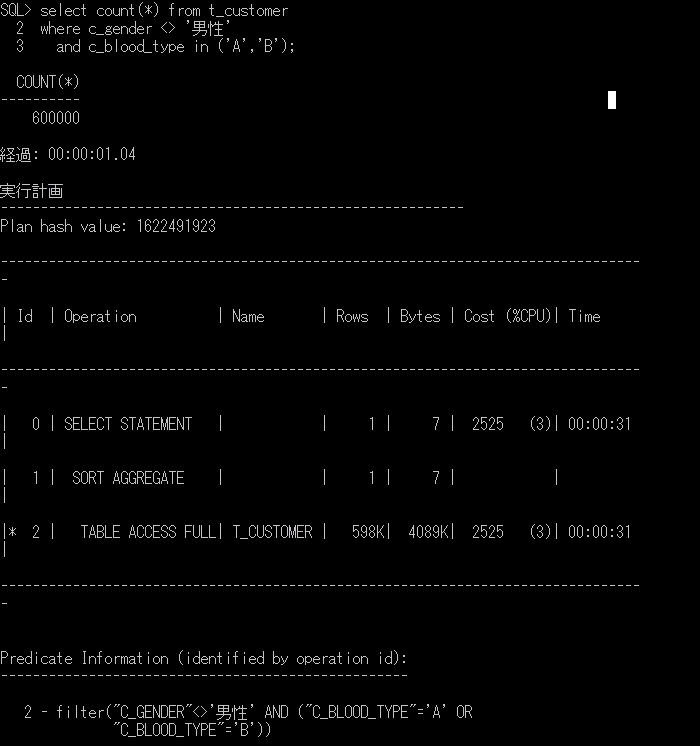
実行計画は、先ほどのインデックスがないときと同じで、特に追加したインデックスを使用しない動作になっています。
カーディナリティの値が小さい列へのBtreeのインデックスは作成してもあまり効果がないとも言われます(実行するSQLにも当然依ります)が、DBがフルスキャンを選択したことは今回のケースではBtreeインデックスは有効ではないことをがわかります。
今度は、先ほどのインデックスを削除し、性別、血液型項目にビットマップインデックスを作成してみます。
CREATE BITMAP INDEX cust_bm_idx2 ON t_customer (c_gender);
CREATE BITMAP INDEX cust_bm_idx3 ON t_customer (c_blood_type);
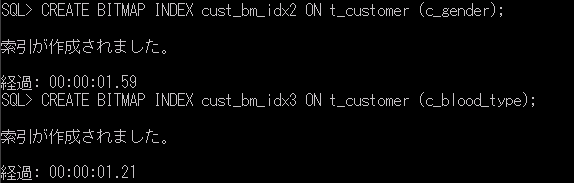
ビットマップインデックスの作成時間はかなり短いですね。
この状態で、再度先ほどの男性以外で、血液型が「A」型と「B」型の人が何人いるかを、同じSQLで実行してみます。
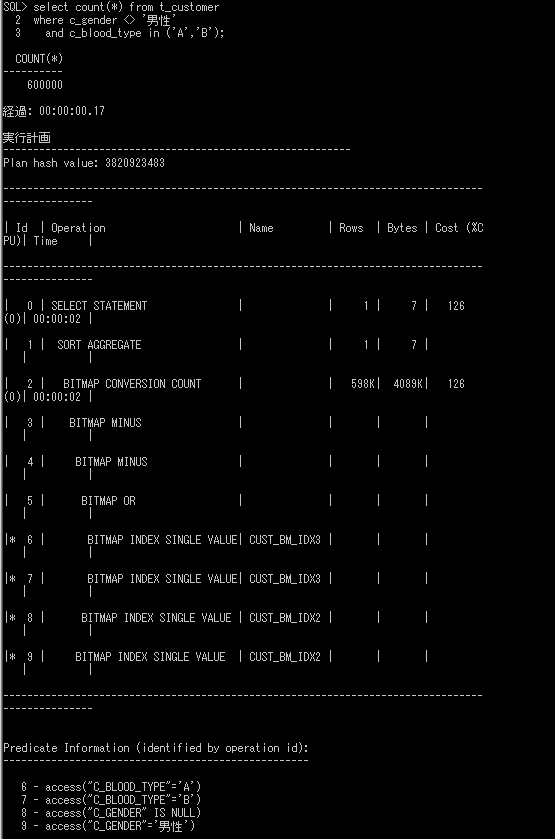
今度は、作成したビットマップインデックスを使用した実行計画になり、処理の実行時間も0.17秒とかなり短縮されることがわかります。このように、データにnullが含まれている場合でも、カーディナリティが低い列であれば、ビットマップインデックスを作成することで、抽出処理が高速化することが確認できると思います。
※ただし、ビットマップインデックスを作成した状態での、データの登録や更新は、b-treeのインデックスがある場合に比べてかなり遅くなることも事実であり、データウェアハウスなどの抽出が中心のデータベースの場合などに絞ったほうがよいようです。
今日は以上まで
にほんブログ村