ITコーディネータのシュウです。

コスモスがとてもきれいだったので写真に撮りました。ここしばらく、仕事のほうが忙しく、なかなかブログを作成できなかったのですが、久しぶりの投稿です。
さて、実りの秋、食欲の秋、スポーツの秋、読書の秋、いろいろな言葉で表現される秋もかなり深まってきました。
私も先月は、妻に引っ張られながら、なまった体に鞭打って運動会にも何とか頑張って参加しました。子供の学校においては、高校では文化祭、中学では合唱のクラス対抗発表会などもあり、たまには父親らしいことをしようと、子供たちの姿を見に行って来ました。
プロ野球は日本シリーズが終わり、今はプレミア12が始まっています。日本は3連勝で頑張っていますね。体操の世界選手権では日本が37年ぶりの金メダル、そして、内村航平選手が、前人未到の個人総合6連覇! いやあ、挙げ出すといろいろありますね。そしてみんな頑張っているんですよね。私も、ちょっと疲れているけど、頑張るぞ!
...と気合は入れてみたんですが、なかなか力が出ないのも事実。今日は久しぶりに早く帰ろうかな~。
<本日の題材>
ファンクションインデックス
いろいろなシステムを担当すると、あるデータを抽出しなければならないときに、テーブル同士のジョインに、既存のキーとなる項目をそのまま使用することができず、関数を使用して項目を加工したかたちで条件を設定しなければならない場合に時折遭遇します。
そんなとき、データ件数が多い場合には、インデックスをうまく使えないために処理時間がかなりかかってしまい、問題になることがあります。
最近の開発案件でもそういうケースがあり、どうしたらよいかを検討したところ、ORACLEの機能にファンクションインデックスというものがあり、それを使うことで処理時間を短縮することができました。
今日は、それを取り上げてみたいと思います。
実際に行ったケースはちょっと複雑だったため、簡単な例で試してみたいと思います。
テーブル「TAB_C」、テーブル「TAB_D」があり、定義は以下のようだとします。
CREATE TABLE TAB_C(
C_CODE_1 VARCHAR2(20)
,C_数量 NUMBER(12)
,CONSTRAINT PK_TAB_C PRIMARY KEY (C_CODE_1));
CREATE TABLE TAB_D(
D_CODE_1 VARCHAR2(20)
,D_数量 NUMBER(12)
,CONSTRAINT PK_TAB_D PRIMARY KEY (D_CODE_1));
データを以下のように作成します。
TAB_Cの「C_CODE_1」は、最初の文字が「C」で後は1からの連番、TAB_Dの「D_CODE_1」は、最初の文字が「D」で後は1からの連番とします。また、C_数量、D_数量については、1~1000000 の間のランダムな整数を設定することにします。
DECLARE
v_count NUMBER := 0;
v_ccode VARCHAR2(20) := ' ';
v_dcode VARCHAR2(20) := ' ';
BEGIN
WHILE v_count < 1000000 LOOP
v_count := v_count + 1;
v_ccode := 'C'||CAST(v_count AS VARCHAR2);
v_dcode := 'D'||CAST(v_count AS VARCHAR2);
INSERT INTO TAB_C(C_CODE_1, C_数量)VALUES
(v_ccode, FLOOR(DBMS_RANDOM.VALUE(1, 1000001)));
INSERT INTO TAB_D(D_CODE_1, D_数量)VALUES
(v_dcode, FLOOR(DBMS_RANDOM.VALUE(1, 1000001)));
END LOOP;
END;
/
※DBMS_RANDOM.VALUEは乱数を取得するのに使えます。
データの作成結果を確認してみます。
SELECT * FROM TAB_C
ORDER BY CAST(SUBSTR(C_CODE_1,2,LENGTH(C_CODE_1)-1) AS NUMBER);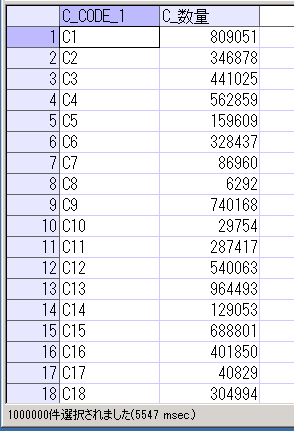
SELECT * FROM TAB_D
ORDER BY CAST(SUBSTR(D_CODE_1,2,LENGTH(D_CODE_1)-1) AS NUMBER);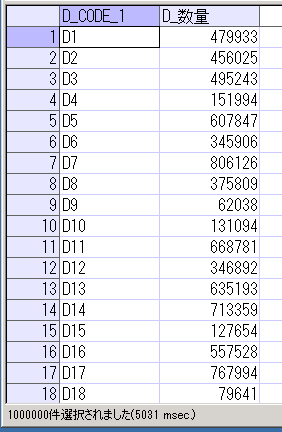
TAB_C、TAB_Dとも1000000件作成されていて、数量はランダムな整数(1~1000000の間)になっているのが確認できます。
この2つのテーブルは、それぞれのテーブルの主キーである「C_CODE_1」「D_CODE_1」の2桁目以下の値でジョインすることで、1対1のデータを抽出できます。
このときのジョインの条件は、例えば以下のようになります。
SUBSTR(C_CODE_1,2,LENGTH(C_CODE_1)-1) = SUBSTR(D_CODE_1,2,LENGTH(D_CODE_1)-1)
この場合、C_CODE_1、C_CODE_2は、それぞれのテーブルのプライマリーキーであったとしても、SUBSTRやLENGTHという関数を使っているためにうまくインデックスを使った検索をしてくれない(全件検索になる)ので、テーブル件数が多い場合には、処理時間が非常にかかってしまいます。
実際に、ジョインした結果を抽出してみます。
(条件として、キーの2桁目以降が700000~710000のものに絞っています)
SELECT
SUBSTR(C_CODE_1,2,LENGTH(C_CODE_1)-1), SUBSTR(D_CODE_1,2,LENGTH(D_CODE_1)-1)
FROM TAB_C C
JOIN TAB_D D
ON SUBSTR(C_CODE_1,2,LENGTH(C_CODE_1)-1) = SUBSTR(D_CODE_1,2,LENGTH(D_CODE_1)-1)
WHERE SUBSTR(C_CODE_1,2,LENGTH(C_CODE_1)-1) BETWEEN 700000 AND 710000
ORDER BY SUBSTR(C_CODE_1,2,LENGTH(C_CODE_1)-1);
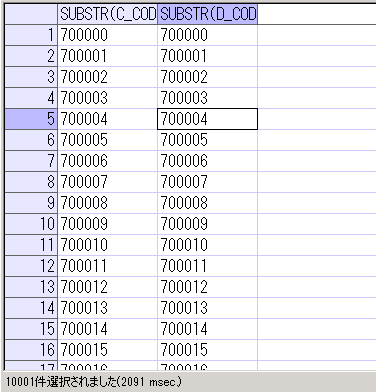
実際に実行計画を取得してみると、
------------------------ 実行計画 --------------------------
SELECT STATEMENT Cost = 126399
SORT ORDER BY
HASH JOIN
TABLE ACCESS FULL TAB_C
TABLE ACCESS FULL TAB_D
-----------------------------------------------------------------
「TAB_C」「TAB_D」とも「TABLE ACCESS FULL」となっていて、フルスキャンしていることがわかります。
そこで、ファンクションインデックスを作成してみます。
CREATE INDEX IX_TAB_C_FUNC ON TAB_C
(SUBSTR(C_CODE_1,2,LENGTH(C_CODE_1)-1));
CREATE INDEX IX_TAB_D_FUNC ON TAB_D
(SUBSTR(D_CODE_1,2,LENGTH(D_CODE_1)-1));
ファンクションインデックスは、索引自体と索引が定義される表が分析されるまで、使用されないということなので、分析します。
EXEC DBMS_STATS.GATHER_TABLE_STATS(OWNNAME => 'BLOG_TEST', TABNAME => 'TAB_C');![]()
EXEC DBMS_STATS.GATHER_TABLE_STATS(OWNNAME => 'BLOG_TEST', TABNAME => 'TAB_D');![]()
この状態で、再度、先ほどのSQLの実行計画を取得してみます。
------------------------ 実行計画 --------------------------
SELECT STATEMENT Cost = 1445
SORT ORDER BY
HASH JOIN
INDEX FAST FULL SCAN IX_TAB_C_FUNC
INDEX FAST FULL SCAN IX_TAB_D_FUNC
-----------------------------------------------------------------
すると、確かに作成したファンクションインデックス「IX_TAB_C_FUNC」「IX_TAB_D_FUNC」が利用されていることが確認できますし、COSTもかなり小さな値になっています。
実際の抽出結果は、
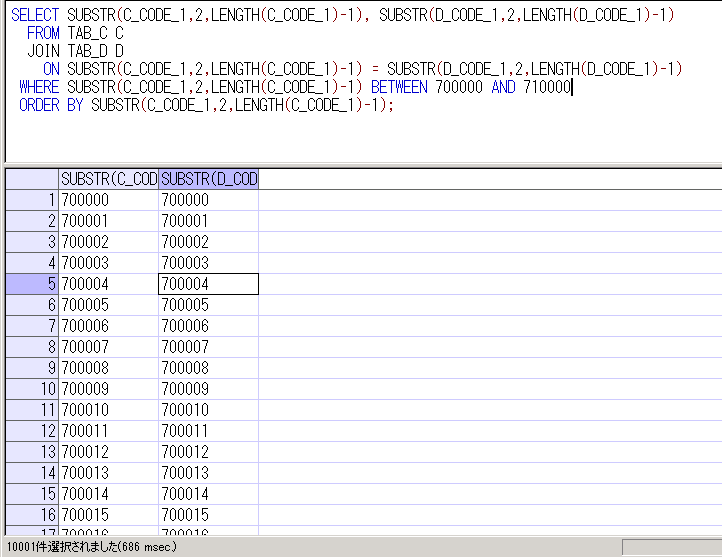
処理自体、先ほどよりは早く結果が返って来ました。
こういうケースで、ファンクションインデックスを作成することは、レスポンス改善としては効果があることが分かります。
今日は以上まで
にほんブログ村