ITコーディネータのシュウです。


ちょっと前に、出雲神話で有名な島根県に行く機会があり、時間があったので、たくさんの銅鐸が出土した加茂岩倉遺跡と、銅剣がたくさん出土した荒神谷遺跡を見に行って来ました。上の写真が加茂岩倉遺跡、下が荒神谷遺跡です。
もともと神話など、古代の歴史に興味があったこともあり、出雲には何かあるような気がして、この考古学上の歴史的な発見であった2つの遺跡に是非行ってみたかったので、とてもいい機会でした。
アマテラスの弟で出雲族の祖とされ、ヤマタノオロチ退治で有名なスサノオノミコト、イナバノ白ウサギで有名な国造りを行ったオオクニヌシノミコト、そして出雲の国譲りなどいろいろな話しが残されています。古代の日本において、邪馬台国がどこにあったのか、そして大和朝廷がどのようにつくられていったのか、いろいろな説がありますが、とても興味深い内容ですね。いつか、真実が明らかにされる日が来るのを楽しみにしたいと思います。
いよいよ、今年も残すところあとわずかになりました。いつの間にか年末になってしまったという感じです。今年も1年間いろいろとありがとうございました。なかなか忙しく、記事をアップする頻度がとても少なくなってしまいましたが、来年も頑張って記事を書ければと思っていますので、どうぞよろしくお願いいたします!
<本日の題材>
照合順序(SQL Server)
SQL Serverで、データの文字の大小関係を比較する場合の基準となるものを、照合順序(Collation)と呼んでいます。例えば、アルファベットの「a」「A」、かなの「あ」「ア」「ア」を小さいほうから順に並べたらどう並ぶか、漢字の「川」「皮」ではどちらが大きいのかなどの、文字の大小関係を決めているものになります。
様々なシステムでは、データを名前順に並べるとか、データが一致するものを検索するなどの処理が多々存在します。この照合順序が異なれば、クエリの結果が違ってきてしまうため、この文字の大小関係を決める照合順序というものはとても重要な要素になります。
SQL Serverの照合順序には、SQL照合順序とWindows照合順序の2種類があるとのことですが、SQL照合順序はUnicode データ型をサポートしていなかった SQL Server 6.5 以前のバージョンとの互換性のみを目的としている照合順序であるため、基本的に照合順序と言えば、Windows照合順序のことと考えればよいようです。
それでは、例をあげて照合順序について確認してみます。
あるデータベースの照合順序を確認してみると、「Japanese_CI_AS」となっていますが、他にも、CS、KS、WSなどのオプションがあります。例えば、「Japanese_90_CS_AS_KS_WS_SC」。
それぞれを簡単に説明すると、
・Japanese:辞書順に並び変えた場合の並び順が、日本語辞書順であることを表しています。ただし、ソート順の定義で、
Japanese, Japanese_XJIS, Japanese_Bushu_Kakusu, Japanese_Unicode
などの種類があります。
・90:照合順序のバージョンを表しています。 90 はバージョン 9.0 である SQL Server 2005、100 はバージョン 10.0 である SQL Server 2008 を表しています。
・CS:大文字と小文字を区別します。このオプションを設定すると、大文字より小文字が先に並べ替えられます。
・AS:濁音・半濁音・アクセントの有無を区別します。このオプションを選択しないと、濁音・半濁音・アクセントが区別されません。
・KS:ひらがなとカタカナを区別します。このオプションを選択しないと、ひらがなとカタカナは同じものと見なされます。
・WS:全角文字と半角文字を区別します。このオプションを選択しないと、同じ文字の全角表記と半角表記は同じものと見なされます。
・SC:SQL Server 2012 以降で、辞書順に並べる場合に補助文字を認識するかどうかを区別します。
また、並び順は、辞書順ではなくバイナリ順 (ビット配列順、文字コード順、コードポイント順) もあります。バイナリ順の照合順序の名前は、Japanese_90_BIN や Japanese_90_BIN2 のように CS_AS_KS_WS の部分が BIN または BIN2 となります。
「Japanese_CI_AS」となっているデータベースで具体的に試してみます。「大小比較」というテーブルを作成し、そこに、下記のようにデータを登録し、データを抽出してみます。
insert into dbo.大小比較(no, 文字) values(1,'あ');
insert into dbo.大小比較(no, 文字) values(2,'ア');
insert into dbo.大小比較(no, 文字) values(3,'ア');
insert into dbo.大小比較(no, 文字) values(4,'皮');
insert into dbo.大小比較(no, 文字) values(5,'川');
insert into dbo.大小比較(no, 文字) values(6,'革');
insert into dbo.大小比較(no, 文字) values(7,'大');
insert into dbo.大小比較(no, 文字) values(8,'題');
insert into dbo.大小比較(no, 文字) values(9,'1');
insert into dbo.大小比較(no, 文字) values(10,'1');
insert into dbo.大小比較(no, 文字) values(11,'a');
insert into dbo.大小比較(no, 文字) values(12,'A');
select * from dbo.大小比較
order by no;
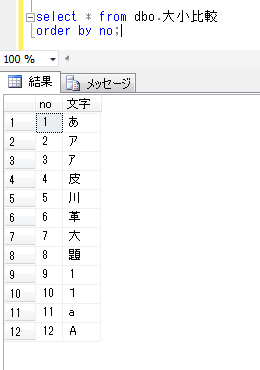
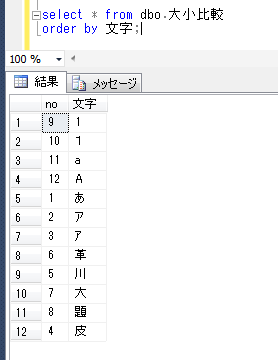
select * from dbo.大小比較
order by 文字;
次に、条件として、「1」に等しいものを抽出してみます。
select * from dbo.大小比較
where文字 = '1'
order by 文字;
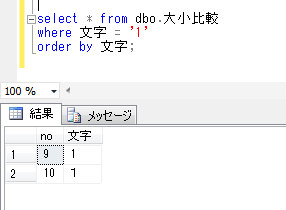
全角と半角が同じものとして認識されているのが確認できます。
同様に、条件として、「あ」に等しいものを抽出してみます。
select * from dbo.大小比較
where文字 = 'あ'
order by 文字;
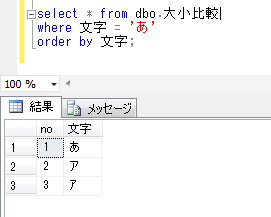
ひらがなとカタカナが同じものとして認識されているのが確認できます。
上記の内容を区別するためには、オプションの部分を変更する必要があります。
ここで、このテーブルを含む「TEST」データベースの照合順序を変更してみます。
ALTER DATABASE TEST COLLATE Japanese_CI_AS_KS_WS;

データベースの照合順序を変更した状態で、先ほどのSQLを実行してみます。
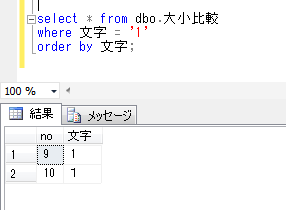
何故か、結果は同じです。これは、データベースの照合順序を変更しても、既存のテーブルの照合順序は変更されないためで、下記のように項目について照合順序を設定してテーブルを変更する必要があります。
ALTER TABLE dbo.大小比較
ALTER COLUMN 文字 varchar(20)
COLLATE Japanese_CI_AS_KS_WS;
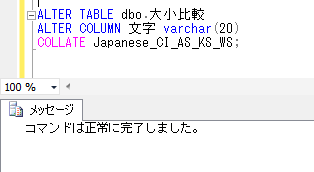
この状態で、再度、前回行ったSQLを実行してみます。
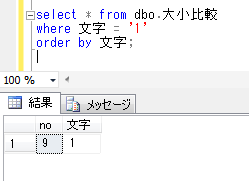
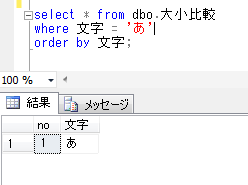
全角と半角文字、ひらがなとカタカナが区別されて、それぞれ該当する1行のみが抽出されるようになりました。
今日は以上まで
にほんブログ村