ITコーディネータのシュウです。

いよいよ梅雨の季節が近づいてきました。上の写真は、少し前に娘がスマホで撮って送ってくれたきれいな夕方の空です。少し神秘的ですね。梅雨になるとこういう空もなかなか見れなくなっちゃうな。
さて、最近のスポーツでは、サッカーのワールドカップがいよいよ始まります。2か月前に監督の交代劇があり、このところの強化試合も負け続けているので、難しいと思っちゃいますが、どうか奇跡よ起きて~! 2002年の日韓共催のワールドカップのベスト16を超えてほしい!
また、卓球では先日の荻村杯・ジャパンオープンで、男子は張本智和選手、女子では伊藤美誠選手が優勝しました。接戦を最後まで粘って勝ち切った精神力は本当にすごい、感動します。日本選手が頑張っていると、元気が湧いてきます。よーし、仕事も頑張るぞー!
<本日の題材>
動的管理ビュー(SQL Server)
SQL Serverを使用していて、パフォーマンスがいまいちよくない場合など、最もCPUを多く使っているクエリーは何か?、最も多くのI/Oを発生させているクエリは何か?、不足しているインデックスはないか?などを確認したくなることがあると思います。そんなときに、知っていると便利な動的管理ビューについて、今回は取り上げてみたいと思います。
SQL Serverというと、パフォーマンスモニターや利用状況モニターなど、GUIのツールでいろいろと調べるというイメージが強く、逆にOracleは、V$表といわれる動的パフォーマンスビューなどを駆使していろいろと調べるというイメージが強いですね。(最近はOracleもEnterprise ManagerなどでGUIでも見れるかたちにしてきていますが)
ただ、SQL Serverでも、動的管理ビューというものから、いろいろと上記のような内容を調査することができます。
ちなみに、動的管理ビュー(DMV:Dynamic Management View)は、SQL Server2005で追加された機能で、パフォーマンス・チューニングを手掛けるエンジニアにとっては画期的といえるものでした。それまで、ほとんどドキュメント化されず、その状態を参照する方法も知らされていなかったSQL Serverの内部が、広く可視化されたからです。
それでは、以下に例を挙げてみましょう。
●最もCPUを多く使っているクエリーの上位10位までを確認する
SELECT TOP 10
total_worker_time/execution_count AS avg_cpu_cost,
execution_count,
SUBSTRING(st.text, (qs.statement_start_offset/2)+1,
((CASE qs.statement_end_offset
WHEN -1 THEN DATALENGTH(st.text)
ELSE qs.statement_end_offset
END - qs.statement_start_offset)/2) + 1) AS query_text,
query_plan
FROM sys.dm_exec_query_stats AS qs
CROSS APPLY sys.dm_exec_sql_text(sql_handle) AS st
CROSS APPLY sys.dm_exec_query_plan(plan_handle) AS qp
ORDER BY avg_cpu_cost DESC;
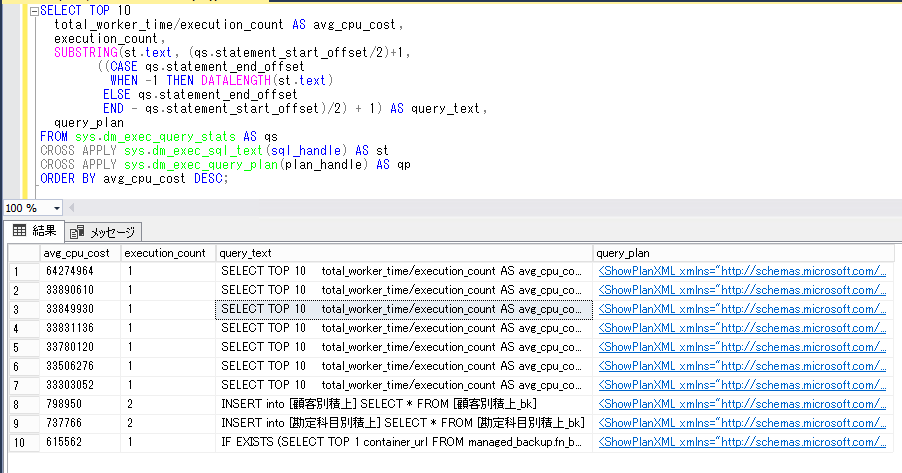
上記は、「sys.dm_exec_query_stats」という動的管理ビューから抽出できる情報で、「total_worker_time」(プランの実行で使用されたcpu時間の合計)を「execution_count」(プランが実行された回数)で割った値を平均のcpuコストとして、それの多い順に10件を表示しています。ただし、実行頻度(execution_count)が少なければ、それほど重要ではないと思われます。
(※注意点としては、現在キャッシュされているクエリに対する集計情報のみを示していること。メモリが多くなければ、過去に行ったコストの高いクエリがキャッシュから削除されている可能性もあるので、定期的にこの抽出を行えば、コストの高いクエリを特定できる可能性が高くなると思われます。)
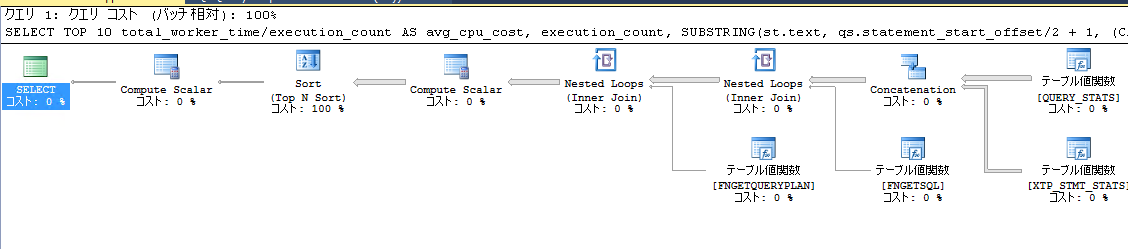
なお、上記のSQLでは、前回取り上げた「CROSS APPLY」を使用しています。また、「querry_plan」の列を最後に表示していますが、これをクリックすると、以下のように「querry_text」で表示されたSQLの実行時の実行プランが表示できます。(ただし、一緒に表示するとその分抽出処理が重たくなると思われるので、後から plan_handleを元に実行プランを抽出することも可能です。)
●最も多くのI/Oを発生させているクエリの上位10位までを確認する
SELECT TOP 10
(qs.total_logical_reads/qs.execution_count) AS avg_logical_reads,
(qs.total_logical_writes/qs.execution_count) AS avg_logical_writes,
(qs.total_physical_reads/qs.execution_count) AS avg_phys_reads,
execution_count,
SUBSTRING(st.text, (qs.statement_start_offset/2)+1,
((CASE qs.statement_end_offset
WHEN -1 THEN DATALENGTH(st.text)
ELSE qs.statement_end_offset
END - qs.statement_start_offset)/2) + 1) AS query_text,
query_plan
FROM sys.dm_exec_query_stats AS qs
CROSS APPLY sys.dm_exec_sql_text(sql_handle) AS st
CROSS APPLY sys.dm_exec_query_plan(plan_handle) AS qp
ORDER BY (total_logical_reads + total_logical_writes) DESC;
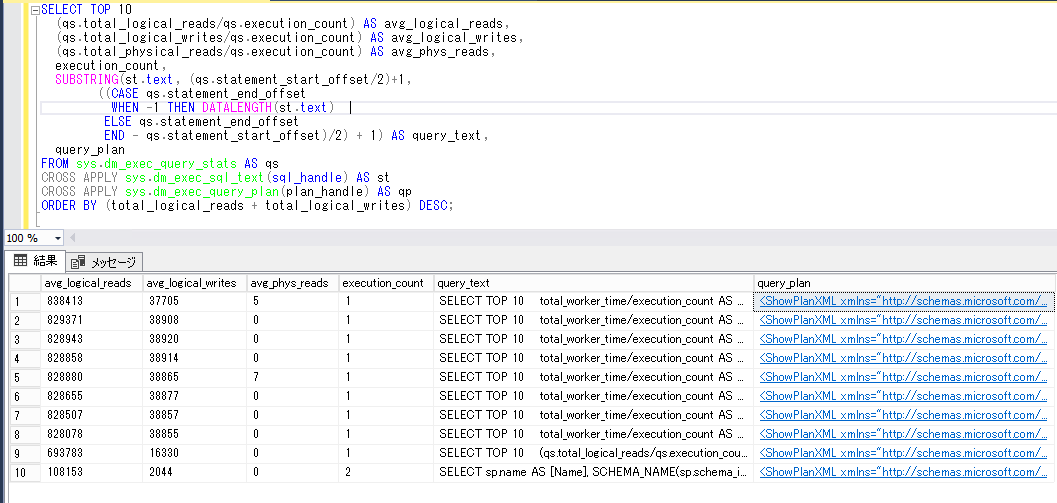
こちらは、「total_logical_reads」(論理読み取りの合計数)と「total_logical_writes」(論理書き込みの合計数)の合計の多いものから順に上位10件を表示しています。
●不足していると思われるインデックスの一覧
SELECT gs.avg_user_impact AS [予測されるクエリパフォーマンス改善率],
gs.avg_total_user_cost AS [削減できたクエリの平均コスト],
gs.last_user_seek AS [最後にシークした時間],
id.statement AS [テーブル名] ,
id.equality_columns AS [等値述語に使用できる列],
id.inequality_columns AS [不等値述語に使用できる列] ,
id.included_columns AS [包括列として必要な列],
gs.unique_compiles AS [コンパイルおよび再コンパイルの数],
gs.user_seeks AS [クエリによって発生したシーク数]
FROM sys.dm_db_missing_index_group_stats AS gs
INNER JOIN sys.dm_db_missing_index_groups AS ig
ON gs.group_handle = ig.index_group_handle
INNER JOIN sys.dm_db_missing_index_details AS id
ON ig.index_handle = id.index_handle
-- WHERE id.[database_id] =DB_ID(‘db名’)
-- コメントをはずすと指定したデータベースでの抽出となる
Order By gs.avg_user_impact DESC;
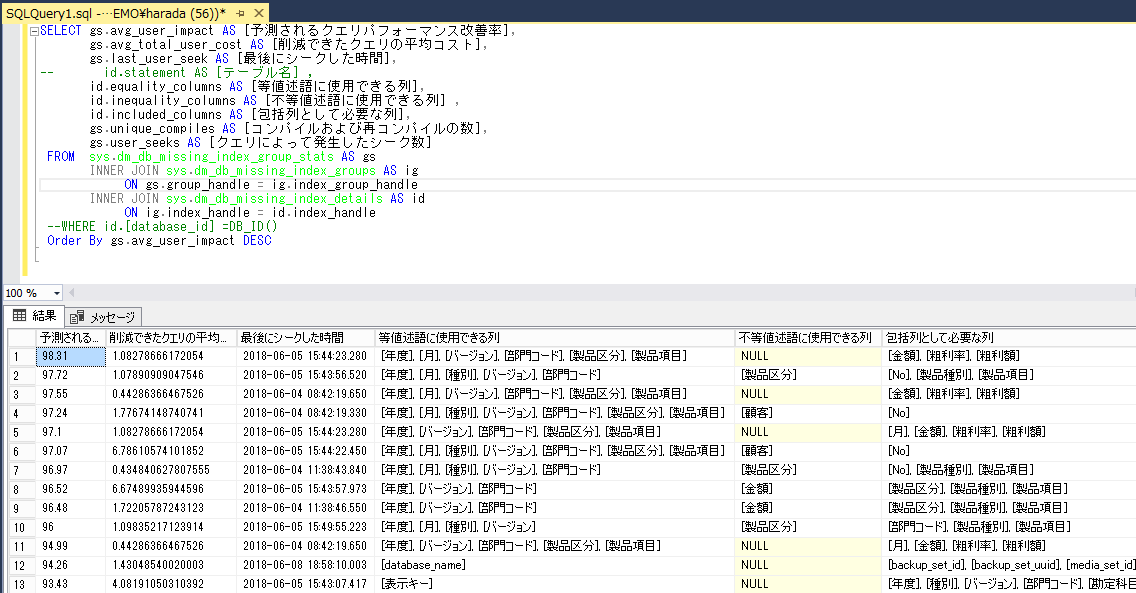
上記は、「sys.dm_db_missing_index_group_stats」「sys.dm_db_missing_index_groups」「sys.dm_db_missing_index_details」という動的管理ビューから抽出できる情報で、インデックスが存在していたなら改善されるであろうパフォーマンス改善率などを表示するものになっています。
上記の動的管理ビューの結果からインデックスを追加作成するとした場合には、[equality_columns(等値述語に使用できる列)]を最初に指定し、その次に、[inequality_columns(不等値述語に使用できる列)]を指定し、INCLUDE句に[included_columns(包括列として必要な列)]を指定するかたちになります。
※参考:https://docs.microsoft.com/ja-jp/previous-versions/sql/sql-server-2008-r2/ms345405(v=sql.105)
例えば、1番目の結果からインデックスを追加するとしたら、
CREATE NONCLUSTERED INDEX [KEY1_製品区分別積上] ON [dbo].[製品区分別積上]
(
[年度], [月], [バージョン], [部門コード], [製品区分], [製品項目]
)
INCLUDE (
[金額], [粗利率], [粗利額]
);
レスポンス改善を行いたいときに、結構有効かも知れませんね。
今日は以上まで
にほんブログ村