ITコーディネータのシュウです。

この写真は、前回のブログで写真を載せた、大根島にある「由志園」に行ったときに、ついでに訪れた、島根半島の先のほうにある「美保神社」で撮ったものです。私も高校生の時に一度兄に連れて行ってもらったことがあったというかすかな記憶がありましたが、それ以来なので、ほとんど初めてという感じでした。この神社の祭神は、えびす様(事代主神)と大国主神の后の三穂津姫で、商売繁盛、海上安全、五穀豊穣、夫婦和合などの守護神として祀られています。実家が、毎年、正月には美保神社のお札を送ってもらうようにしているということを、道すがら初めて聞きました。父親も数十年ぶりに参ることができたと喜んでいたので、少し遠回りにはなりましたが、行って良かったと思います。
<本日の題材>
メモリ最適化テーブル変数(SQL Server)
SQL Server2014から実装されたIn-Memory OLTP 機能に、メモリ最適化テーブルというものがあります。今まであまり試したことがなかったのですが、今回は、そのメモリ最適化テーブル変数というものを試してみたいと思います。
例)
テスト用テーブルを作成し、テストデータを50万件作成します。そこから検索したいデータを抽出し、テスト用テーブルの列定義と同じ設定のメモリ最適化テーブル変数に登録して、結果を抽出してみます。
まず、メモリ最適化機能を使用するために、データベースに MEMORY_OPTIMIZED_DATA で宣言された FILEGROUPを作る必要があります。今回は、既存のデータベース「BLOG」に追加します。
ALTER DATABASE BLOG ADD FILEGROUP BLOG_mod CONTAINS MEMORY_OPTIMIZED_DATA;
ALTER DATABASE BLOG ADD FILE (name='BLOG_mod1', filename='C:\Program Files\Microsoft SQL Server\MSSQL12.MSSQLSERVER\MSSQL\DATA\iBLOG_mod1') TO FILEGROUP BLOG_mod;

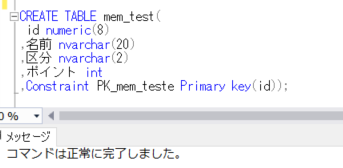
次に、データを登録する「 mem_test」テーブルを作成します。
CREATE TABLE mem_test(
id numeric(8)
,名前 nvarchar(20)
,区分 nvarchar(2)
,ポイント int
,Constraint PK_mem_teste Primary key(id));
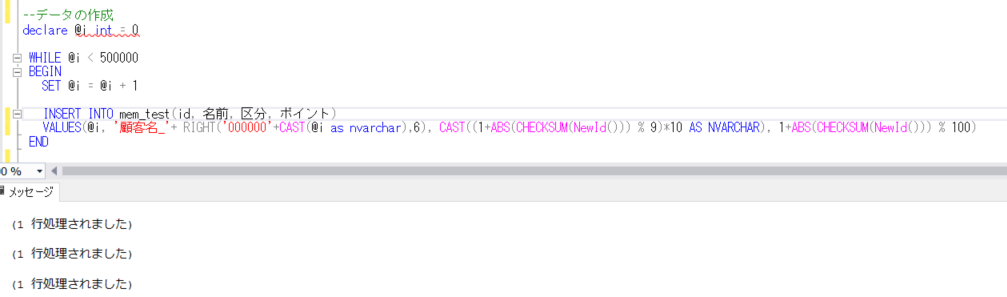
このテーブルにテストデータを作成します。今回は、50万件を以下のように作成します。「id」項目には、1~500000までシーケンシャルに値を設定し、名前は「顧客名_」の後にidを頭0埋めで設定、区分は2桁で、10,20,30, ~90までをランダムに、ポイントは、1~100の整数をランダムに登録してみます。ランダムに値を設定するのは、RAND関数と、NewID関数を使用してみます。
--データの作成
DECLARE @i int = 0
WHILE @i < 500000
BEGIN
SET @i = @i + 1
INSERT INTO mem_test(id, 名前, 区分, ポイント)
VALUES(@i, '顧客名_'+ RIGHT('000000'+CAST(@i as nvarchar),6), CAST(FLOOR(1 + RAND()*9)*10 AS NVARCHAR), 1+ABS(CHECKSUM(NewId())) % 100)
END
ランダム値についてですが、RAND関数は、0~1の間の数が生成されるので、指定範囲内の整数値乱数が必要な場合は、
SELECT FLOOR([FROM値] + (RAND() * ([TO値] - [FROM値] + 1)))
のようにすれば取得できます。今回は、10,20,..,90 という文字型の値にしたかったので、CAST(FLOOR(1 + RAND()*9)*10 AS NVARCHAR) としました。
また、NEWID関数は、uniqueidentifier データ型の値を返してきますが、データを数値にしてチェックするCHECKSUM関数と、負の数が返ってくる場合もあるため絶対値を取得するABS関数を使い、さらに求める値の範囲を考慮して、今回は1~100までの値のため、100で割った余りを使うかたちで、1+ABS(CHECKSUM(NewId())) % 100 としました。
データを確認してみます。
SELECT * FROM mem_test
ORDER BY id;

区分とポイントはランダムに値が登録されているのが確認できました。
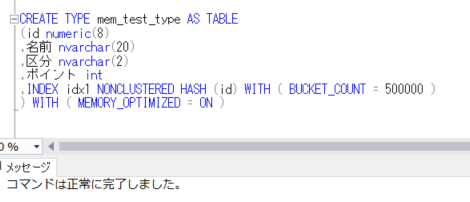
それでは、メモリ最適化テーブル変数を使用するために、そのためのユーザー定義テーブル型を宣言します。通常と違うのは、「MEMORY_OPTIMIZED = ON」を付けることと、ハッシュインデックスを付与する点が異なります。
CREATE TYPE mem_test_type AS TABLE
(id numeric(8)
,名前 nvarchar(20)
,区分 nvarchar(2)
,ポイント int
,INDEX idx1 NONCLUSTERED HASH (id) WITH ( BUCKET_COUNT = 500000 )
) WITH ( MEMORY_OPTIMIZED = ON );
※HASHインデックスでは、BUCKET_COUNT(バケット数)を適切な値へ設定していないと、性能低下の原因に繋がるようです。(特に小さすぎると性能が大きくさがるとのこと)
ちなみに、最初に行った、データベースに MEMORY_OPTIMIZED_DATA で宣言された FILEGROUPを作成していなかった場合には、上記のタイプを作成しようとしたときに、「メモリ最適化テーブル を作成できません。メモリ最適化テーブル を作成するには、オンライン状態かつ 1 つ以上のコンテナーがある MEMORY_OPTIMIZED_FILEGROUP がデータベースに含まれている必要があります。」というエラーが出ます。

それでは、上記を使ってメモリ最適化テーブル変数を宣言し、指定した5つの区分についてのデータ件数を確認してみたいと思います。
-- メモリ最適化テーブル変数の宣言
DECLARE @retValue dbo.mem_test_type
-- メモリ最適化テーブルへデータの INSERT
DECLARE
@区分1 nvarchar(2) = '20',
@区分2 nvarchar(2) = '40',
@区分3 nvarchar(2) = '50',
@区分4 nvarchar(2) = '70',
@区分5 nvarchar(2) = '90';
INSERT INTO @retValue
SELECT id, 名前, 区分, ポイント
FROM dbo.mem_test
WHERE 区分 = @区分1
OR 区分 = @区分2
OR 区分 = @区分3
OR 区分 = @区分4
OR 区分 = @区分5
-- メモリ最適化テーブル変数に格納した結果を集計
SELECT 区分, COUNT(*) 件数
FROM @retValue
GROUP BY 区分
ORDER BY 区分;
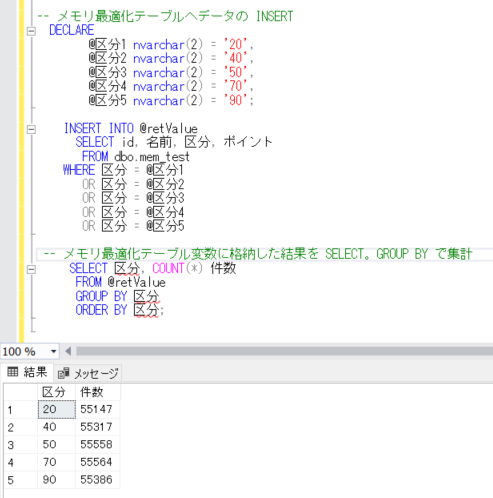
ほとんど時間はかからずに結果が抽出されてきました。
メモリ最適化テーブル変数を、一時テーブルのようなかたちで使用できることが確認できましたが、実際には、もっと適した使用法があるのではないかと思います。今回は、取りあえず使えることを確認してみました。
今日は以上まで
にほんブログ村